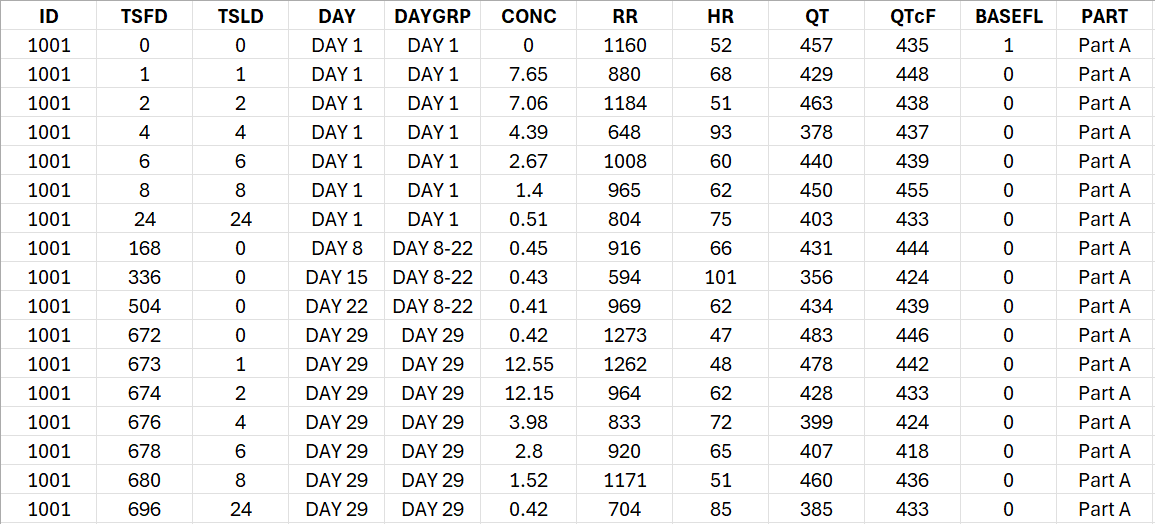
Original data
This example is a simulated dataset meant to show how to deal with ECG records spanning over multiple days. There is no placebo data and all individuals have received the same treatment, with a dose once a day for one month. The PK and ECG measurements were dense on day 1 and 29, and only at pre-dose on day 8, 15 and 22.
The csv file we will start from contains the following columns. The TSFD column is the time since the first dose, while TSLD is the time since the last dose. The DAY column indicates the study day while the days with sparse sampling have been regrouped together for stratification purpose in the DAYGRP column. We have a single pre-dose baseline for each individual, at time 0 of day 1.
Data processing
In order to use the provided R functions, the R script mlxQTcTools.R must be sourced. In addition, a monolixSuite installation must be available and the lixoftConnectors R package installed. In order to indicate the location of the MonolixSuite installation, the functioninitQTc(path=...) is used.
source('../_mlxQTcTools/mlxQTcTools.R')
initQTc(path="C:/Program Files/Lixoft/MonolixSuite2024R1")
In the initial dataset, the QTc has already been calculated, the triplicates have been averaged but the baseline QTc and HR columns must still be added. In order to perform a concentration-QTc analysis, the steps that remain to be applied are:
-
add the BLQTc and BLHR by identifying baseline records from BASEFL = 1
-
calculate the baseline-corrected QTc, i.e ΔQTc.
-
for exploratory data visualization purpose, calculate the ΔHR
-
add columns to be used as covariates in the model, or regressor for visualization purpose: the centered QTc baseline, time as categorical factor, concentration and RR interval duration.
The steps can be performed using the function process_QTcData():
process_QTcData(data="data_multiDays.csv",
QTname = "QT", RRname = "RR", CONCname = "CONC", TRTname = NULL,
IDname = "ID", TIMEname = "TSLD", addVariables = "DAY",
bComputeBaseline = T, BLFLAGname = "BASEFL",
baselineType = "predose", bComputeBLperAddVar = F,
bComputeQTc = F, QTCname = "QTcF",
outName = "data_multiDays_formatted.csv", silent=F)
The column containing the QT, RR, HR, drug concentration, treatment (placebo or drug), subject id and time are indicated using the arguments QTname, RRname, CONCname, IDname, TIMEname. The TRTname is left to NULL because all individuals have received the same treatment. For the TIMEname column, we use TSLD, because this is the column we want to use as factor in the model. By default, the function will average records for the same ID and TIME. Given that the time restarts at zero for each day, it is necessary to average records by ID, TIME and DAY. This is specified using addVariables = "DAY".
Given that the QTc column (heart rate-corrected QT) is already present in the dataset, it does not need to be computed and we set bComputeQTc = FALSE. The name of the QTc column is indicated using the QTCname argument.
The QTc baseline and HR baseline columns must be added to the dataset. We thus use bComputeBaseline = TRUE and indicating the arguments BLFLAGname = "BASEFL" containing the flags for baseline records. The type of baseline is indicated with baselineType = "predose". When an additional variable is provided, the baseline can be identical for all categories of the additional variable or different. Here we have a single baseline record applying to all days, so we set bComputeBLperAddVar = F.
The name of the output file is given via the outName argument.
Running the function on the Ranolazine example generates the following console output:
Info: Given that no 'TRTname' column has been defined, the dataset is assumed to have no placebo data and a single treatment.
Info: The HR column has not been provided and has thus been calculated based on the 'RR' column.
Info: The BLQTc and BLHR columns have been calculated for each ID, using the lines flagged as BASEFL=Y or 1.
Info: The dQTc and dHR columns have been calculated as dQTc=QTc-BLQTc and dHR=HR-BLHR.
Info: The BLQTc_cent column has been calculated as BLQTc_cent=BLQTc-mean(BLQTc).
Info: There is no placebo data, ddQTc will not be calculated.
Info: The Cc_reg (concentration as regressor), RR_reg (RR as regressor) and TIME_cat (TIME as categorical covariate) columns have been added.
==> Created new dataset data_multiDays_formatted.csv.
The Info lines give details about the data processing steps. The console output can be avoided using silent=T.
Note that ΔΔQTc could not be computed because we have no placebo data. The QTcF which was already present have been renamed to follow the standard name required for the generateAllQTcProjects()function.
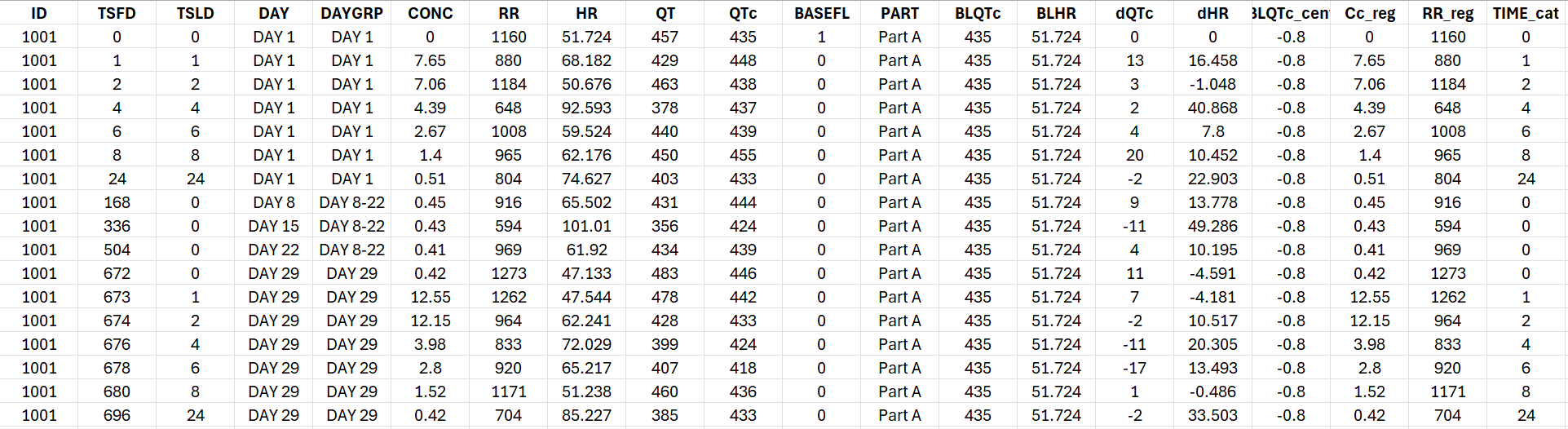
The generated formatted dataset is the following. It contain all columns needed to create a Monolix project for conc-QTc analysis as well as creating the usual exploratory data analysis plots.
Model fitting
The next step is to generate and run Monolix projects to estimate the parameters of the concentration-ΔQTc models. Both linear and non-linear conc-QTc relationships are considered.
To generate and run the Monolix projects to run the con-QTc analysis, the function generateAllQTcProjects() is used.
generateAllQTcProjects(dataSet="data_multiDays_formatted.csv",
IDname="ID", TIMEname="TSLD", TRTname=NULL, CONCname="CONC",
placeboName = "no placebo", baselineType="predose",
addVariables = "DAY", refCategory = "DAY 1",
addStratCatCov = "DAYGRP",
modelFolder="../_mlxQTcTools/models/dQTcModels/",
projectFolder="./mlx_runs/",
isddQTC = FALSE,
bRun = TRUE)
The user should provide the formatted dataset in the argument dataSet, as well as the name of the columns containing the subject id in IDname, time in TIMEname, and concentration in CONCname. The TRTname is left NULL because there is a single treatment. The other columns (e.g QT, QTc, HR, etc) must have predefined headers and do not need to be specified.
To specify that there is no placebo data, one can indicate placeboName = "no placebo". In case of ECG records over multiple days, the Garnett et al. white paper suggest to use the time within the day and the day as factors in the model. We thus use TIMEname="TSLD" and addVariables = "DAY". By default, the reference category for the additional variable will be the first one in alphabetical order of the categories present in the DAY column. To specify explicitly the reference category, we use refCategory = "DAY 1".
For the report later on, instead of using the DAY column to stratify plots, we will use the DAYGRP column in which the days with a single record have been regrouped. To make this possible, it is necessary to generate a Monolix project where this column is tagged as categorical covariate (even if it is not used in the model). This is specified with addStratCatCov = "DAYGRP".
The folder containing the structural models to be used to generate the monolix runs are given in the argument modelFolder. The R package contains a pre-written library of models with linear, Emax, Emax with sigmoidicity and loglinear conc-QTc relationship. User-defined models can be added to this folder is needed. In folder in which the runs are generated is the projectFolder argument.
Whether conc-ΔΔQTc or conc-ΔQTc should be run is indicated using isddQTC = T or F. To run the projects after having created them, use bRun = T.
When running the function, the console output indicates the generated runs, the implemented models and the progress of the parameter estimation:
Created project ./mlx_runs/dQTc_Emax.mlxtran with model:
dQTc = (theta0 + eta0) + theta3 * TIME_cat + theta4 * BLQTc_cent + (theta2 + eta2) * Conc/(Conc + theta5) + theta6 * DAY
Running project... Done.
Created project ./mlx_runs/dQTc_EmaxSigma.mlxtran with model:
dQTc = (theta0 + eta0) + theta3 * TIME_cat + theta4 * BLQTc_cent + (theta2 + eta2) * Conc^theta6/(Conc^theta6 + theta5^theta6) + theta7 * DAY
Running project... Done.
Created project ./mlx_runs/dQTc_Linear.mlxtran with model:
dQTc = (theta0 + eta0) + theta3 * TIME_cat + theta4 * BLQTc_cent + (theta2 + eta2) * Conc + theta5 * DAY
Running project... Done.
Created project ./mlx_runs/dQTc_Linear_effectComp.mlxtran with model:
dQTc = (theta0 + eta0) + theta3 * TIME_cat + theta4 * BLQTc_cent + (theta2 + eta2) * Ce + theta5 * DAY with dCe/dt = (Conc - Ce)/theta5
Running project... Done.
Created project ./mlx_runs/dQTc_LogLinear.mlxtran with model:
dQTc = (theta0 + eta0) + theta3 * TIME_cat + theta4 * BLQTc_cent + (theta2 + eta2) * log(1 + Conc/theta5) + theta6 * DAY
Running project... Done.
Note that in the absence of placebo data, the pre-specified model has been modified and does not contain the TRT term. In addition, the DAY has been added as a factor.
The generated Monolix runs can be opened with the Monolix GUI for inspection.
Report generation
A standard report can be generated using the function quarto_render() and a Quarto template. The quarto template will read the results from generated Monolix projects and generate a report including:
-
Exploratory data analysis (data summary, QT/QTc, heart rate correction, baseline QTc, ΔQTc and concentration-time)
-
Model assumption assessments (heart-rate independence from drug concentration, QTc independence from heart rate, linearity of the concentration-QTc relationship, immediate effect of concentration change on ΔQTc change)
-
Modeling results (comparison of the different models, model fit, parameter estimates, goodness of fit)
-
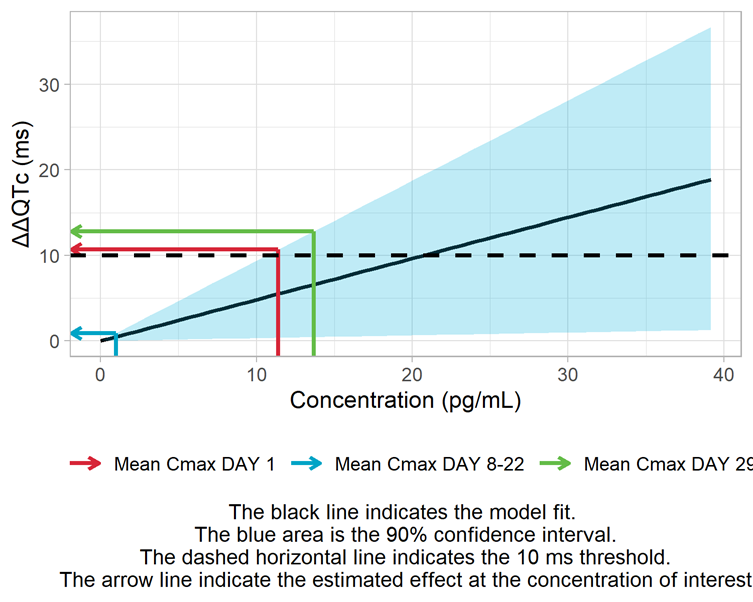
Derivation of the ΔΔQTc prediction intervals, including assessment of the 10-ms threshold
The quarto function is called in the following way:
quarto_render(input = "../_mlxQTcTools/QTc_quarto_allModels.qmd",
output_file = "MultiDays_dQTc_report.docx",
execute_params = list(folderName = "../Example_multipleDays/mlx_runs", # give relative path from quarto template (.qmd) to folder containing runs
compoundName = "LIX1234",
CONCcolumn = "CONC",
TRTcolumn = NULL,
STRATcolumn = "DAYGRP",
STRATname = "Day",
bHasPlacebo = FALSE,
concentrationLabel = "Concentration",
concentrationUnit = "pg/mL",
studyType = "dQTc",
nBins = 10))
The input is the quarto template. A standard quarto template is provided in the package but it can also be adjusted to the users need. The output_file indicates the name of the generated report as word document. The execute_params list the folder containing the Monolix runs in folderName, the string to be used as compound name in compoundName, the column of the formatted dataset containing the concentration in CONCcolumn. The TRTcolumn is set to NULL but DAYGRP column to be use for plot stratification is indicated in STRATcolumn = "DAYGRP", and the header/label to be used for the stratification column in STRATname. Then comes a logical to indicate whether the dataset contains placebo data in bHasPlacebo, the type of study using studyType = "dQTc", the concentration unit in concentrationUnit(for plot labels), the number of bins to average the concentration in nBins, and the BICc threshold to consider that an alternative model is better than the linear model in thresBICc.
Note that the folderName must indicate the relative path from the .qmd template (not the R working directory) to the folder containing the runs.
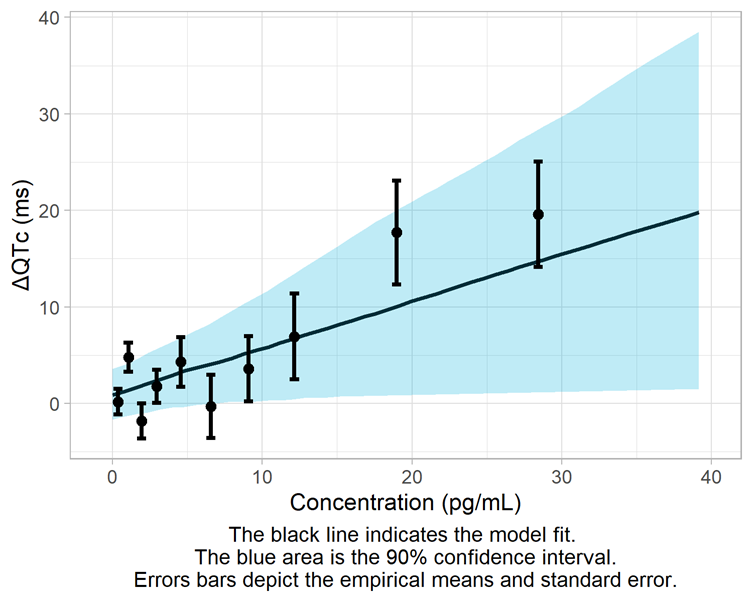
The generated report can be visualized below:

The word version of the report can be download here.
Conclusion
The conc-ΔQTc data for this drug is best captured by the standard prespecified linear model. The upper bound of the 90% confidence interval at the geometric mean maximum concentration is 12.8 ms and slightly exceeds the 10 ms threshold.