
Conc-QTc Modeling
Pre-specified linear model
The Garnett et al. White Paper suggests to use a linear model with concentration effect, treatment effect, time effect and centered baseline effect:
with i the individual, j the treatment and k the time. The ϴ parameters represent fixed effects and the η terms indicate random effects. It is assumed the random effects are normally distributed with mean 0 and an unstructured covariance matrix. The residual error are normally distributed with mean 0 and a constant variance.
Variations to the pre-specified model
Specific situations require adaptations of the pre-specified model, as listed in Table 4 of Garnett et al.
ΔΔQTc as dependent variable
In crossover studies where each individual receives both placebo and active treatment, it is possible to compute ΔΔQTc for each individual by subtracting the ΔQTc for placebo from the ΔQTcF for each treatment arm. In this case, ΔΔQTc can be modeled directly, leading to a simpler model. With the intercept (ϴ0,pop+η0,i) and time point terms, ϴ3,T1*I(TIME=T1) + ϴ3,T2*I(TIME=T2) + ..., being identical for active and placebo treatment, these terms cancel out. The parameter ϴ1 denoting the treatment effect for ΔQTc becomes the intercept for ΔΔQTc (without random effects). A new covariate appears, the difference between centered baselines of the treatment and the placebo group.
The model reads:
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c45)'%3e%3cuse xlink:href='%23MJMAIN-394' x='0' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-394' x='833' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='1667' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='2458' y='0'%3e%3c/use%3e%3cg transform='translate(3163%2c0)'%3e%3cuse xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(433%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='624' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-3D' x='4784' y='0'%3e%3c/use%3e%3cg transform='translate(5840%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-31' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='6986' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='7986' y='0'%3e%3c/use%3e%3cg transform='translate(8376%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='9522' y='0'%3e%3c/use%3e%3cg transform='translate(10522%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B7' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(497%2c-253)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='11915' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2217' x='12527' y='0'%3e%3c/use%3e%3cg transform='translate(13249%2c0)'%3e%3cuse xlink:href='%23MJMATHI-43' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(715%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='624' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='15097' y='0'%3e%3c/use%3e%3cg transform='translate(16098%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-34' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='17243' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-42' x='17966' y='0'%3e%3c/use%3e%3cg transform='translate(18726%2c0)'%3e%3cuse xlink:href='%23MJMATHI-4C' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(681%2c-163)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-65' x='433' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6E' x='900' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-74' x='1500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1862' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-41' x='2140' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-64' x='2891' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='3414' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-50' x='3827' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6C' x='4578' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
with
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c3)'%3e%3cuse xlink:href='%23MJMATHI-42' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(759%2c0)'%3e%3cuse xlink:href='%23MJMATHI-4C' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(681%2c-163)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-65' x='433' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6E' x='900' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-74' x='1500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1862' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-41' x='2140' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-64' x='2891' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='3414' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-50' x='3827' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6C' x='4578' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-3D' x='5267' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='6323' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='6713' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='7504' y='0'%3e%3c/use%3e%3cg transform='translate(8209%2c0)'%3e%3cuse xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(433%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-3D' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-31' x='1815' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='2315' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='2594' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-3D' x='3115' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='3894' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2013' x='11849' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6D' x='12517' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-65' x='13395' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-61' x='13862' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6E' x='14391' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='14992' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='15381' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='16173' y='0'%3e%3c/use%3e%3cg transform='translate(16877%2c0)'%3e%3cuse xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(433%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-3D' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-31' x='1815' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='2315' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='2594' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-3D' x='3115' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='3894' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='20518' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-29' x='20908' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2212' x='21519' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='22520' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='22909' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='23701' y='0'%3e%3c/use%3e%3cg transform='translate(24405%2c0)'%3e%3cuse xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(433%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-3D' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='1815' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='2315' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='2594' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-3D' x='3115' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='3894' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2013' x='28046' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6D' x='28714' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-65' x='29592' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-61' x='30059' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6E' x='30588' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='31189' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='31578' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='32370' y='0'%3e%3c/use%3e%3cg transform='translate(33074%2c0)'%3e%3cuse xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(433%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-3D' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='1815' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='2315' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='2594' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-3D' x='3115' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='3894' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='36715' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-29' x='37104' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
No placebo data
If by design or ethical reasons a concurrent placebo arm was not included, it is not possible to estimate the ϴ1 term associated to the placebo vs active treatment. The Garnett et al white paper also suggests to remove the ϴ3 term associated to the time effect. When time-matched baseline record are used, diurnal variations are already corrected for and the ϴ3 term is indeed not needed (see next section). However, when datasets without placebo data use predose baselines, Orihashi et al have shown that including categorical time effects in the model leads to less biased estimates and better controlled false negative rates.
The model thus reads:
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c45)'%3e%3cuse xlink:href='%23MJMAIN-394' x='0' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='833' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='1625' y='0'%3e%3c/use%3e%3cg transform='translate(2329%2c0)'%3e%3cuse xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(433%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-3D' x='4439' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='5495' y='0'%3e%3c/use%3e%3cg transform='translate(5885%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='7030' y='0'%3e%3c/use%3e%3cg transform='translate(8031%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B7' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(497%2c-253)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='9424' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2B' x='10035' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='11036' y='0'%3e%3c/use%3e%3cg transform='translate(11426%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='12571' y='0'%3e%3c/use%3e%3cg transform='translate(13572%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B7' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(497%2c-253)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='14965' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2217' x='15576' y='0'%3e%3c/use%3e%3cg transform='translate(16299%2c0)'%3e%3cuse xlink:href='%23MJMATHI-43' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(715%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='18635' y='0'%3e%3c/use%3e%3cg transform='translate(19636%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(469%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-33' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='21347' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='22070' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-49' x='22775' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-4D' x='23279' y='0'%3e%3c/use%3e%3cg transform='translate(24331%2c0)'%3e%3cuse xlink:href='%23MJMATHI-45' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1044' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='25760' y='0'%3e%3c/use%3e%3cg transform='translate(26761%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-34' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='27906' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='28629' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='29019' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='29810' y='0'%3e%3c/use%3e%3cg transform='translate(30515%2c0)'%3e%3cuse xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(433%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-3D' x='1836' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='2615' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2013' x='33251' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6D' x='33918' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-65' x='34797' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-61' x='35263' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6E' x='35793' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='36393' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='36783' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='37574' y='0'%3e%3c/use%3e%3cg transform='translate(38279%2c0)'%3e%3cuse xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(433%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-3D' x='1836' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='2615' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='41015' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-29' x='41405' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Time-matched baseline
Time-matched baseline adjustments use the corresponding predose QTc measurements collected prior to drug administration on Day -1. A time-matched baseline adjustment may be used when placebo data are not available, in order to minimize the effect of diurnal variation in QTc. In case of time-matched baseline, diurnal variations are already corrected for and the ϴ3 term is not needed.
The model reads:
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c45)'%3e%3cuse xlink:href='%23MJMAIN-394' x='0' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='833' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='1625' y='0'%3e%3c/use%3e%3cg transform='translate(2329%2c0)'%3e%3cuse xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(433%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-3D' x='4439' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='5495' y='0'%3e%3c/use%3e%3cg transform='translate(5885%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='7030' y='0'%3e%3c/use%3e%3cg transform='translate(8031%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B7' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(497%2c-253)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='9424' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2B' x='10035' y='0'%3e%3c/use%3e%3cg transform='translate(11036%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-31' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='12182' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='12904' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-52' x='13609' y='0'%3e%3c/use%3e%3cg transform='translate(14368%2c0)'%3e%3cuse xlink:href='%23MJMATHI-54' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='826' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='15567' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='16568' y='0'%3e%3c/use%3e%3cg transform='translate(16957%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='18103' y='0'%3e%3c/use%3e%3cg transform='translate(19103%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B7' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(497%2c-253)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='20496' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2217' x='21108' y='0'%3e%3c/use%3e%3cg transform='translate(21831%2c0)'%3e%3cuse xlink:href='%23MJMATHI-43' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(715%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='24167' y='0'%3e%3c/use%3e%3cg transform='translate(25168%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-34' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='26313' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='27036' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='27425' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='28217' y='0'%3e%3c/use%3e%3cg transform='translate(28921%2c0)'%3e%3cuse xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(433%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-3D' x='1836' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='2615' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2013' x='31658' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6D' x='32325' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-65' x='33204' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-61' x='33670' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6E' x='34200' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='34800' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='35190' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='35981' y='0'%3e%3c/use%3e%3cg transform='translate(36686%2c0)'%3e%3cuse xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(433%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-3D' x='1836' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='2615' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='39422' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-29' x='39812' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Note that if there is no placebo data, the ϴ1 term also drops out (see section above).
Data over multiple days
If QTc measurements are collected over multiple days, the TIME parameter can be reduced to time after dose on same day and DAY is included in model as an additional factor.
The model reads:
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c792)'%3e%3cuse xlink:href='%23MJMAIN-394' x='0' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='833' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='1625' y='0'%3e%3c/use%3e%3cg transform='translate(2329%2c0)'%3e%3cuse xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(433%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-3D' x='4439' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='5495' y='0'%3e%3c/use%3e%3cg transform='translate(5885%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='7030' y='0'%3e%3c/use%3e%3cg transform='translate(8031%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B7' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(497%2c-253)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='9424' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2B' x='10035' y='0'%3e%3c/use%3e%3cg transform='translate(11036%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-31' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='12182' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='12904' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-52' x='13609' y='0'%3e%3c/use%3e%3cg transform='translate(14368%2c0)'%3e%3cuse xlink:href='%23MJMATHI-54' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='826' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='15567' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='16568' y='0'%3e%3c/use%3e%3cg transform='translate(16957%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='18103' y='0'%3e%3c/use%3e%3cg transform='translate(19103%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B7' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(497%2c-253)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='20496' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2217' x='21108' y='0'%3e%3c/use%3e%3cg transform='translate(21831%2c0)'%3e%3cuse xlink:href='%23MJMATHI-43' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(715%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='24167' y='0'%3e%3c/use%3e%3cg transform='translate(25168%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(469%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-33' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='26879' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='27602' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-49' x='28306' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-4D' x='28811' y='0'%3e%3c/use%3e%3cg transform='translate(29862%2c0)'%3e%3cuse xlink:href='%23MJMATHI-45' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1044' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='31069' y='0'%3e%3c/use%3e%3c/g%3e%3cg transform='translate(0%2c-798)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-34' x='663' y='-213'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2217' x='1145' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='1868' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='2257' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='3049' y='0'%3e%3c/use%3e%3cg transform='translate(3753%2c0)'%3e%3cuse xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(433%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-3D' x='1836' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='2615' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2013' x='6490' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6D' x='7157' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-65' x='8036' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-61' x='8502' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6E' x='9032' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='9632' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='10022' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='10813' y='0'%3e%3c/use%3e%3cg transform='translate(11518%2c0)'%3e%3cuse xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(433%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-3D' x='1836' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='2615' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='14254' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-29' x='14644' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2B' x='15255' y='0'%3e%3c/use%3e%3cg transform='translate(16256%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-35' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='17402' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-44' x='18124' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-41' x='18953' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-59' x='19703' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Non-linear concentration effect
If exploratory plots indicate a non-linear effect of the concentration on ΔQTc, alternative models can be used. Typical non-linear models are Emax, Emax with sigmoidicity (Hill) and loglinear relationships.
Emax model:
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cuse xlink:href='%23MJMAIN-394' x='0' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='833' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='1625' y='0'%3e%3c/use%3e%3cg transform='translate(2329%2c0)'%3e%3cuse xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(433%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-3D' x='4439' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='5495' y='0'%3e%3c/use%3e%3cg transform='translate(5885%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='7030' y='0'%3e%3c/use%3e%3cg transform='translate(8031%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B7' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(497%2c-253)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='9424' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2B' x='10035' y='0'%3e%3c/use%3e%3cg transform='translate(11036%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-31' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='12182' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='12904' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-52' x='13609' y='0'%3e%3c/use%3e%3cg transform='translate(14368%2c0)'%3e%3cuse xlink:href='%23MJMATHI-54' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='826' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='15567' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='16568' y='0'%3e%3c/use%3e%3cg transform='translate(16957%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='18103' y='0'%3e%3c/use%3e%3cg transform='translate(19103%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B7' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(497%2c-253)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='20496' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2217' x='21108' y='0'%3e%3c/use%3e%3cg transform='translate(21608%2c0)'%3e%3cg transform='translate(342%2c0)'%3e%3crect stroke='none' width='4380' height='60' x='0' y='220'%3e%3c/rect%3e%3cg transform='translate(1133%2c788)'%3e%3cuse xlink:href='%23MJMATHI-43' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(715%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cg transform='translate(60%2c-700)'%3e%3cuse xlink:href='%23MJMATHI-43' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(715%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='2336' y='0'%3e%3c/use%3e%3cg transform='translate(3337%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-35' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='26673' y='0'%3e%3c/use%3e%3cg transform='translate(27674%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(469%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-33' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='29385' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='30108' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-49' x='30812' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-4D' x='31317' y='0'%3e%3c/use%3e%3cg transform='translate(32368%2c0)'%3e%3cuse xlink:href='%23MJMATHI-45' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1044' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='33798' y='0'%3e%3c/use%3e%3cg transform='translate(34799%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-34' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='35944' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='36667' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='37056' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='37848' y='0'%3e%3c/use%3e%3cg transform='translate(38552%2c0)'%3e%3cuse xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(433%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-3D' x='1836' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='2615' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2013' x='41289' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6D' x='41956' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-65' x='42835' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-61' x='43301' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6E' x='43831' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='44431' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='44821' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='45612' y='0'%3e%3c/use%3e%3cg transform='translate(46317%2c0)'%3e%3cuse xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(433%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-3D' x='1836' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='2615' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='49053' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-29' x='49443' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Emax with sigmoidicity (Hill equation):
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cuse xlink:href='%23MJMAIN-394' x='0' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='833' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='1625' y='0'%3e%3c/use%3e%3cg transform='translate(2329%2c0)'%3e%3cuse xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(433%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-3D' x='4439' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='5495' y='0'%3e%3c/use%3e%3cg transform='translate(5885%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='7030' y='0'%3e%3c/use%3e%3cg transform='translate(8031%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B7' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(497%2c-253)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='9424' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2B' x='10035' y='0'%3e%3c/use%3e%3cg transform='translate(11036%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-31' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='12182' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='12904' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-52' x='13609' y='0'%3e%3c/use%3e%3cg transform='translate(14368%2c0)'%3e%3cuse xlink:href='%23MJMATHI-54' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='826' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='15567' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='16568' y='0'%3e%3c/use%3e%3cg transform='translate(16957%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='18103' y='0'%3e%3c/use%3e%3cg transform='translate(19103%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B7' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(497%2c-253)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='20496' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2217' x='21108' y='0'%3e%3c/use%3e%3cg transform='translate(21608%2c0)'%3e%3cg transform='translate(342%2c0)'%3e%3crect stroke='none' width='4679' height='60' x='0' y='220'%3e%3c/rect%3e%3cg transform='translate(1282%2c965)'%3e%3cuse xlink:href='%23MJMATHI-43' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(774%2c462)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.5)' xlink:href='%23MJMAIN-36' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cg transform='translate(715%2c-327)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cg transform='translate(60%2c-955)'%3e%3cuse xlink:href='%23MJMATHI-43' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(774%2c462)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.5)' xlink:href='%23MJMAIN-36' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cg transform='translate(715%2c-327)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='2336' y='0'%3e%3c/use%3e%3cg transform='translate(3337%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(469%2c462)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.5)' xlink:href='%23MJMAIN-36' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-35' x='663' y='-435'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='26972' y='0'%3e%3c/use%3e%3cg transform='translate(27973%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(469%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-33' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='29684' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='30407' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-49' x='31111' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-4D' x='31616' y='0'%3e%3c/use%3e%3cg transform='translate(32667%2c0)'%3e%3cuse xlink:href='%23MJMATHI-45' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1044' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='34097' y='0'%3e%3c/use%3e%3cg transform='translate(35098%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-34' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='36243' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='36966' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='37356' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='38147' y='0'%3e%3c/use%3e%3cg transform='translate(38852%2c0)'%3e%3cuse xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(433%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-3D' x='1836' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='2615' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2013' x='41588' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6D' x='42255' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-65' x='43134' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-61' x='43600' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6E' x='44130' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='44730' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='45120' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='45911' y='0'%3e%3c/use%3e%3cg transform='translate(46616%2c0)'%3e%3cuse xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(433%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-3D' x='1836' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='2615' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='49352' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-29' x='49742' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Loglinear model:
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c45)'%3e%3cuse xlink:href='%23MJMAIN-394' x='0' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='833' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='1625' y='0'%3e%3c/use%3e%3cg transform='translate(2329%2c0)'%3e%3cuse xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(433%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-3D' x='4439' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='5495' y='0'%3e%3c/use%3e%3cg transform='translate(5885%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='7030' y='0'%3e%3c/use%3e%3cg transform='translate(8031%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B7' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(497%2c-253)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='9424' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2B' x='10035' y='0'%3e%3c/use%3e%3cg transform='translate(11036%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-31' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='12182' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='12904' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-52' x='13609' y='0'%3e%3c/use%3e%3cg transform='translate(14368%2c0)'%3e%3cuse xlink:href='%23MJMATHI-54' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='826' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='15567' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='16568' y='0'%3e%3c/use%3e%3cg transform='translate(16957%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='18103' y='0'%3e%3c/use%3e%3cg transform='translate(19103%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B7' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(497%2c-253)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='20496' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2217' x='21108' y='0'%3e%3c/use%3e%3cg transform='translate(21831%2c0)'%3e%3cuse xlink:href='%23MJMAIN-6C'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-6F' x='278' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-67' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-28' x='23110' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-31' x='23500' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2B' x='24222' y='0'%3e%3c/use%3e%3cg transform='translate(25223%2c0)'%3e%3cuse xlink:href='%23MJMATHI-43' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(715%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2F' x='27337' y='0'%3e%3c/use%3e%3cg transform='translate(27838%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-35' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='28761' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2B' x='29373' y='0'%3e%3c/use%3e%3cg transform='translate(30373%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(469%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-33' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='32085' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='32807' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-49' x='33512' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-4D' x='34016' y='0'%3e%3c/use%3e%3cg transform='translate(35068%2c0)'%3e%3cuse xlink:href='%23MJMATHI-45' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1044' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='36497' y='0'%3e%3c/use%3e%3cg transform='translate(37498%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-34' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='38644' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='39366' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='39756' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='40547' y='0'%3e%3c/use%3e%3cg transform='translate(41252%2c0)'%3e%3cuse xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(433%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-3D' x='1836' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='2615' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2013' x='43988' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6D' x='44656' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-65' x='45534' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-61' x='46001' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6E' x='46530' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='47131' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='47520' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='48312' y='0'%3e%3c/use%3e%3cg transform='translate(49016%2c0)'%3e%3cuse xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(433%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-3D' x='1836' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='2615' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='51753' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-29' x='52142' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Implementation in Monolix
Monolix is a tool for parameter estimation and model diagnostic for linear and non-linear mixed-effects models. It can thus be used to implement and use the models presented above. The implementation in Monolix requires to slightly reorganize the model into two distinct pieces (still corresponding to the same final equation).
The implementation of the model will be done automatically in the R package. This section is for information purpose but does not need to be applied to the user himself.
Separation into structural and statistical model
In a pharmacometric framework, the pre-specified linear model can be rewritten as a structural model which described the drug effect on ΔQTc:
and a statistical model, which describes the interindividual variability and covariate effects:
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c840)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(469%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-3D' x='1642' y='0'%3e%3c/use%3e%3cg transform='translate(2698%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(469%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-70' x='779' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6F' x='1282' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-70' x='1768' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='5096' y='0'%3e%3c/use%3e%3cg transform='translate(6097%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B7' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(497%2c-253)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='7712' y='0'%3e%3c/use%3e%3cg transform='translate(8712%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-31' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='9858' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='10581' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-52' x='11285' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='12045' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2B' x='12971' y='0'%3e%3c/use%3e%3cg transform='translate(13972%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-34' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='15118' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-42' x='15841' y='0'%3e%3c/use%3e%3cg transform='translate(16600%2c0)'%3e%3cuse xlink:href='%23MJMATHI-4C' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(681%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-65' x='433' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6E' x='900' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-74' x='1500' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='18920' y='0'%3e%3c/use%3e%3cg transform='translate(19921%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(469%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-33' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-54' x='779' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-31' x='1483' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='22116' y='0'%3e%3c/use%3e%3cg transform='translate(22838%2c0)'%3e%3cuse xlink:href='%23MJMATHI-49' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(440%2c-187)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-28' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-54' x='389' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-49' x='1094' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-4D' x='1598' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-45' x='2650' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-3D' x='3414' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-54' x='4193' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-31' x='4897' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-29' x='5398' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='27694' y='0'%3e%3c/use%3e%3cg transform='translate(28694%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(469%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-33' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-54' x='779' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='1483' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='30889' y='0'%3e%3c/use%3e%3cg transform='translate(31612%2c0)'%3e%3cuse xlink:href='%23MJMATHI-49' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(440%2c-187)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-28' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-54' x='389' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-49' x='1094' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-4D' x='1598' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-45' x='2650' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-3D' x='3414' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-54' x='4193' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='4897' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-29' x='5398' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='36245' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2E' x='37023' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2E' x='37468' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2E' x='37913' y='0'%3e%3c/use%3e%3c/g%3e%3cg transform='translate(0%2c-750)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(469%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-3D' x='1642' y='0'%3e%3c/use%3e%3cg transform='translate(2698%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(469%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-70' x='779' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6F' x='1282' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-70' x='1768' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='5096' y='0'%3e%3c/use%3e%3cg transform='translate(6097%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B7' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(497%2c-253)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
This formulation allows for an easy extension to non-linear relationships between ΔQTc and the concentration, by defining alternative structural models. The implementation of the other variations to the pre-specified model are easily implemented by including less or different covariates.
For ϴ0,i, we would like to consider random effects varying from individual to individual (η0,i) and covariates which varies from period to period (TRT, BLQTc_cent) or from time point to time point (TIME). Due to a limitation in Monolix, this forces us to separate the fixed effects and the random effects into two different terms of the structural model.
The structural model we will use is thus:
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-3)'%3e%3cuse xlink:href='%23MJMAIN-394' x='0' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='833' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='1625' y='0'%3e%3c/use%3e%3cg transform='translate(2329%2c0)'%3e%3cuse xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(433%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-3D' x='4439' y='0'%3e%3c/use%3e%3cg transform='translate(5495%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(469%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='7082' y='0'%3e%3c/use%3e%3cg transform='translate(8083%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B7' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(497%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='9698' y='0'%3e%3c/use%3e%3cg transform='translate(10698%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(469%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='12285' y='0'%3e%3c/use%3e%3cg transform='translate(13008%2c0)'%3e%3cuse xlink:href='%23MJMATHI-43' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(715%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
and the individual model is:
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c1571)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(469%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-3D' x='1642' y='0'%3e%3c/use%3e%3cg transform='translate(2698%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(469%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-70' x='779' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6F' x='1282' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-70' x='1768' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='5096' y='0'%3e%3c/use%3e%3cg transform='translate(6097%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-31' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='7242' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='7965' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-52' x='8670' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='9429' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2B' x='10356' y='0'%3e%3c/use%3e%3cg transform='translate(11357%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-34' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='12502' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-42' x='13225' y='0'%3e%3c/use%3e%3cg transform='translate(13984%2c0)'%3e%3cuse xlink:href='%23MJMATHI-4C' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(681%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-63' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-65' x='433' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6E' x='900' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-74' x='1500' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='16305' y='0'%3e%3c/use%3e%3cg transform='translate(17306%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(469%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-33' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-54' x='779' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-31' x='1483' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='19500' y='0'%3e%3c/use%3e%3cg transform='translate(20223%2c0)'%3e%3cuse xlink:href='%23MJMATHI-49' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(440%2c-187)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-28' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-54' x='389' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-49' x='1094' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-4D' x='1598' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-45' x='2650' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-3D' x='3414' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-54' x='4193' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-31' x='4897' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-29' x='5398' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='25078' y='0'%3e%3c/use%3e%3cg transform='translate(26079%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(469%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-33' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-54' x='779' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='1483' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='28273' y='0'%3e%3c/use%3e%3cg transform='translate(28996%2c0)'%3e%3cuse xlink:href='%23MJMATHI-49' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(440%2c-187)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-28' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-54' x='389' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-49' x='1094' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-4D' x='1598' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-45' x='2650' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-3D' x='3414' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-54' x='4193' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='4897' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-29' x='5398' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='33629' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2E' x='34407' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2E' x='34853' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2E' x='35298' y='0'%3e%3c/use%3e%3c/g%3e%3cg transform='translate(0%2c7)'%3e%3cuse xlink:href='%23MJMATHI-3B7' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(497%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-3D' x='1670' y='0'%3e%3c/use%3e%3cg transform='translate(2726%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B7' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(497%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-70' x='779' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6F' x='1282' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-70' x='1768' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='5152' y='0'%3e%3c/use%3e%3cg transform='translate(6153%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B7' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(497%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-3D' x='7823' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-30' x='8880' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2B' x='9602' y='0'%3e%3c/use%3e%3cg transform='translate(10603%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B7' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(497%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-30' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg transform='translate(0%2c-1481)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(469%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-3D' x='1642' y='0'%3e%3c/use%3e%3cg transform='translate(2698%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(469%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-70' x='779' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6F' x='1282' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-70' x='1768' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='5096' y='0'%3e%3c/use%3e%3cg transform='translate(6097%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B7' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(497%2c-253)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='779' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
The term ϴ0,i now contains only fixed effects: the intercept ϴ0,pop and the covariate effects ϴ1, ϴ3,k, and ϴ4. The term η0,i represents the random effects for the intercept. We will fix its typical value η0,pop to zero such that the term contains only random effects. The slope remains as before with a random and a fixed component.
Structural model in mlxtran language
In Monolix, the structural model is defined via a txt file using mlxtran language. The concentration is passed as a regressor (to be read directly from the dataset) and its effect is defined in the structural model.
The content of the mlxtran file for the linear model for ΔQTc is:
[LONGITUDINAL]
input = {Cc, dQTc0, eta_dQTc0, slope}
Cc = {use=regressor}
EQUATION:
dQTc = dQTc0 + eta_dQTc0 + slope*Cc
OUTPUT:
output = dQTc
with dQTc0 corresponding to the ϴ0,i individual parameter (with fixed effect and covariate effects), eta_dQTc0 corresponding to η0,i (random effects only) and slope corresponding to the ϴ2,i individual parameter (with fixed effect and random effects).
Statistical model in the GUI
The statistical model is defined in the graphical user interface (or via the lixoftConnectors).
For ΔQTc, we will set:
-
dQTc0: normal distribution to ensure that covariate are added linearly into the model, no random effects, and covariates TRT (categorical), TIME (categorical) and BLcent (continuous), -
eta_dQTc: normal distribution, with random effects, and typical population value fixed to zero, -
slope: normal distribution with random effects.
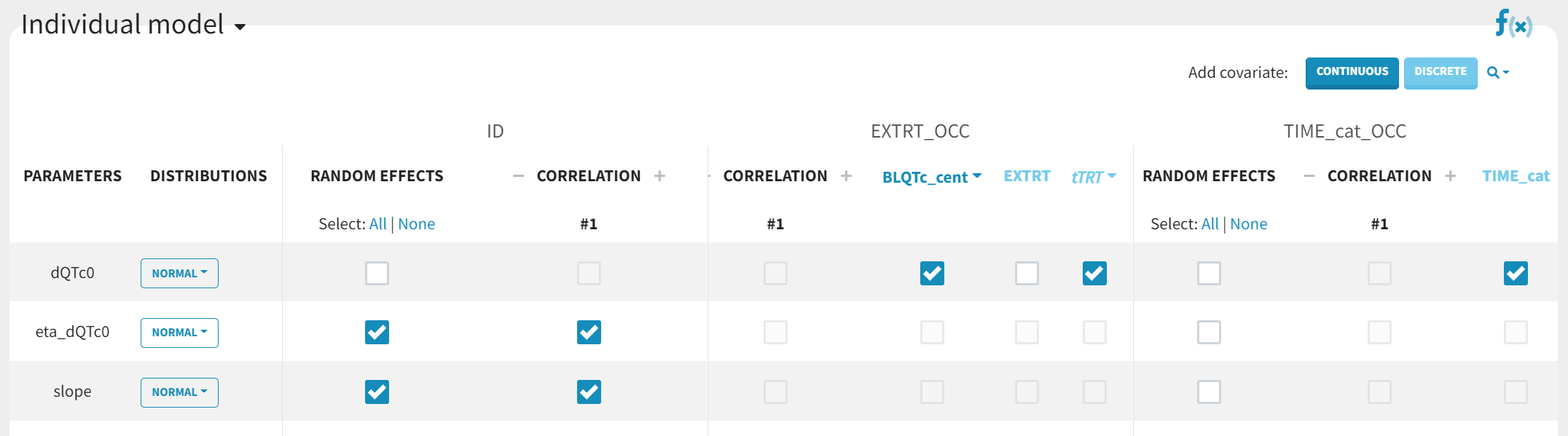
The equations corresponding to this setup can be displayed with the “equation” icon:

The typical value for the eta_dQTc0 parameter is fixed to zero in the Initial Estimates tab.
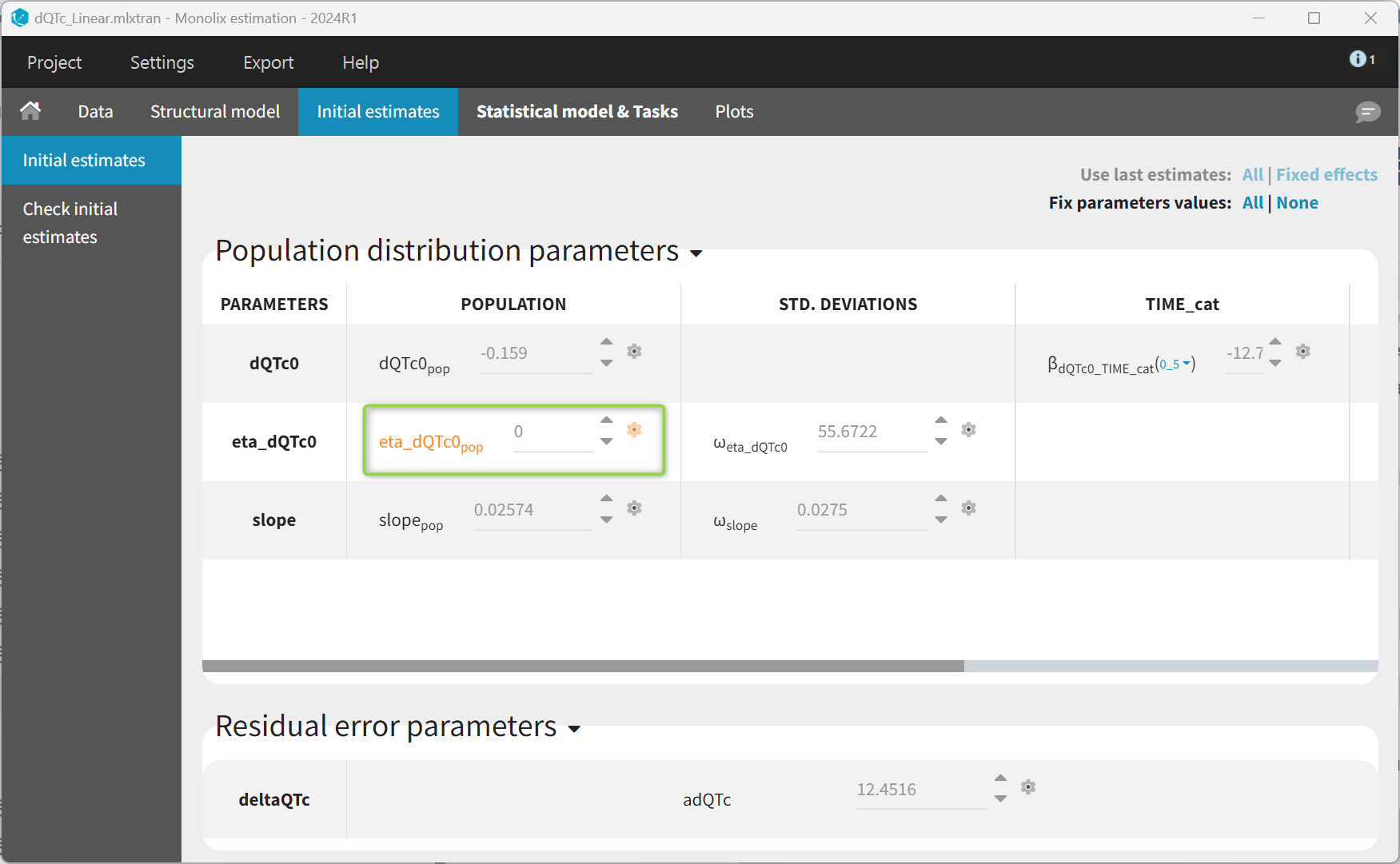
We consider correlations between the random effects (which corresponds to an unstructured covariance structure) and a constant residual error model, as suggested in Garnett et al.
Parameter estimation
Running the “population parameters” task will estimate the model parameters using the SAEM algorithm. The standard errors task will estimation the Fisher information matrix (FIM), the variance-covariance matrix of the estimates and the corresponding relative standard errors (RSE). They represent the uncertainty of the estimated parameters and will be used in the next section to compute the confidence interval.
Model-derived ΔΔQTc at concentration(s) of interest
Derivation of the ΔΔQTc equation
The conc-ΔQTc model is used to compute the ΔΔQTc at concentrations of interest. The concentrations of interest are typically concentrations at the therapeutic dose in a patient population
taking into account possible concentration increase due to drug interactions, impaired hepatic or renal function, and polymorphisms in CYP enzymes. The concentrations of interest should be inside the range of observed concentrations used to generate the model, such that the model is used for interpolation but not extrapolation.
The PD metric of interest is ΔΔQTc, the change from baseline QTc adjusted for placebo. It is calculated as the difference between the model-derived ΔQTc at the concentrations of interest and model-derived ΔQTc for placebo with concentration = 0.
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-3)'%3e%3cuse xlink:href='%23MJMATHI-6D' x='0' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-65' x='878' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-61' x='1345' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6E' x='1874' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='2475' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-394' x='2864' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-394' x='3698' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='4531' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='5323' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-63' x='6027' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-29' x='6461' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-3D' x='7128' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6D' x='8184' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-65' x='9063' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-61' x='9529' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6E' x='10059' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='10659' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-394' x='11049' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='11882' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='12674' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-63' x='13378' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-7C' x='13812' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6A' x='14090' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-3D' x='14780' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-31' x='15837' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2C' x='16337' y='0'%3e%3c/use%3e%3cg transform='translate(16782%2c0)'%3e%3cuse xlink:href='%23MJMATHI-43' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(715%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-3D' x='19174' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-43' x='20230' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-29' x='20991' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2212' x='21603' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6D' x='22603' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-65' x='23482' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-61' x='23948' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6E' x='24478' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='25078' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-394' x='25468' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='26301' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='27093' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-63' x='27797' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-7C' x='28231' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6A' x='28509' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-3D' x='29200' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-30' x='30256' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2C' x='30756' y='0'%3e%3c/use%3e%3cg transform='translate(31202%2c0)'%3e%3cuse xlink:href='%23MJMATHI-43' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(715%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='624' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='1036' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6B' x='1315' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-3D' x='33593' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-30' x='34650' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-29' x='35150' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Because the intercept (ϴ0,pop+η0,i) and time point terms, ϴ3,T1*I(TIME=T1) + ϴ3,T2*I(TIME=T2) + ..., are identical for the two terms, they cancel out. The parameter ϴ1 (treatment effect) which is present only for the first term remains. The BLQTc_cent is assumed to be null on average and is ignored. The random effects for the slope η2,i are also averaged by the mean. We thus obtain:
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-6)'%3e%3cuse xlink:href='%23MJMATHI-6D' x='0' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-65' x='878' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-61' x='1345' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6E' x='1874' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-394' x='2752' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-394' x='3586' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-51' x='4419' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-54' x='5211' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-63' x='5915' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='6349' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-43' x='6738' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-29' x='7499' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-3D' x='8166' y='0'%3e%3c/use%3e%3cg transform='translate(9222%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(469%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-31' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-45' x='779' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-73' x='1543' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-74' x='2013' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='11693' y='0'%3e%3c/use%3e%3cg transform='translate(12694%2c0)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(469%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2C' x='500' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-45' x='779' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-73' x='1543' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-74' x='2013' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2217' x='15165' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-43' x='15887' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
with Est denoting the estimate of the true value.
To calculate the confidence interval, an analytical formula can be derived when the linear model is used (see Garnett et al.), based on the standard errors of the estimates. However, this formula cannot be generalized when non-linear models are used. An alternative would be to use non-parametric bootstrap, but this would require many runs. In Monolix, we can use the variance-covariance matrix of the estimates (from which the standard errors are derived) to sample sets of (ϴ1, ϴ2) parameters which capture their uncertainty, instead of using bootstrap replicates. Each set is used to generate a ΔΔQTc prediction and the 90% confidence interval is calculated based on these predictions, as described in Garnett. et al.
The resulting plot overlays the ΔΔQTc model prediction (black line), its 90% prediction interval capturing the uncertainty (blue band), the 10 ms increase in ΔΔQTc threshold (dashed line) and the upper limit of the prediction interval at the concentration of interest (blue arrow).
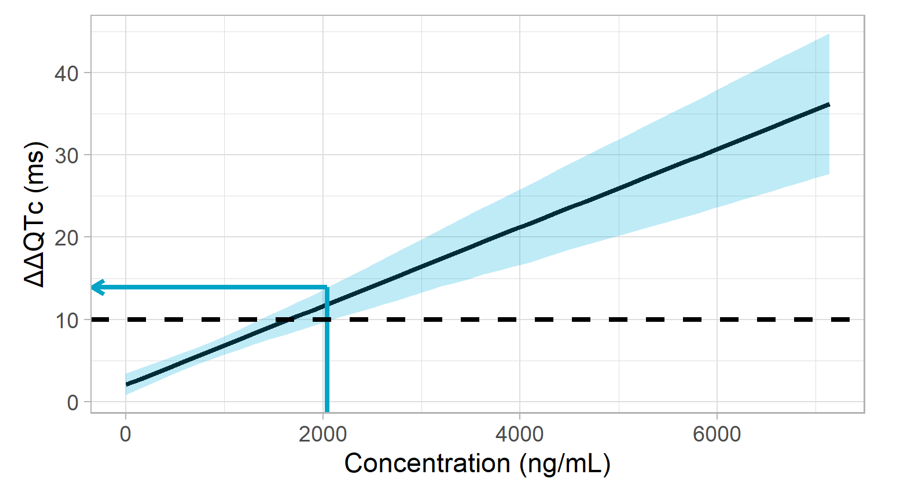
Implementation in Simulx
In order to reuse directly the developed model for ΔQTc, we will calculate the ΔΔQTc as the difference between the model-derived ΔQTc at the concentrations of interest and model-derived ΔQTc for placebo with concentration = 0.
To perform the model prediction, the Monolix project is exported to Simulx. We will consider two simulation groups, one for the active treatment and one for the placebo.
The simulation setup is the following:
-
parameters: the random effects are ignored and the fixed effects are sampled from the uncertainty distribution. This is done by selecting the element “mlx_TypicalUncertainLin”.
-
covariates: the TRT covariates is set to 1 for the active group and 0 for the placebo. The values for the BLQTc_cent and TIME covariates are set to 0 and will anyway cancel out.
-
concentration: a fine grid of concentrations of interest is defined, via the regressor element. For the placebo group, the concentration is set to zero.
-
replicates: 500 replicates are used, each corresponding to a different set of population parameters sampled from the covariance matrix of the estimates (uncertainty distribution)
-
group size: for each replicate, a single simulation is done (as the random effects are ignored, all simulations would be identical)
Outside of Simulx, we compute ΔΔQTc as the difference between the predictions of the two groups, for each replicates. The 5th, median and 95th percentiles over replicates is finally computed.
This procedure for both linear and non-linear models and any included covariates.