
Overview
This example demonstrates the efficiency of Message Passing Interface (MPI) parallelization in MonolixSuite for a large-scale quantitative systems pharmacology (QSP) job.
The benchmark used here is a Neuro-Dynamic QSP model with 4056 subjects and 20 iterations of SAEM.
The results illustrate how distributing the workload across multiple compute nodes significantly reduces execution time compared to single-node symmetric multiprocessing (SMP) execution.
Benchmark Configuration
|
Parameter |
Description |
|---|---|
|
Model |
Neuro-Dynamic QSP |
|
SAEM Iterations |
20 |
|
Nodes |
1 – 20 |
|
Cores per node |
96 |
|
Parallel modes tested |
SMP (1 node) and MPI (1 – 20 nodes) |
Results Summary
|
Parallel Mode |
# of Nodes |
# of Cores |
Wallclock Time (mins) |
Speed-up (fold) |
|---|---|---|---|---|
|
SMP |
1 |
96 |
55 |
1.0 |
|
MPI |
1 |
96 |
43 |
1.3 |
|
MPI |
2 |
192 |
25 |
2.2 |
|
MPI |
3 |
288 |
18 |
3.0 |
|
MPI |
4 |
384 |
13.8 |
4.0 |
|
MPI |
5 |
480 |
12 |
4.6 |
|
MPI |
10 |
960 |
8 |
6.9 |
|
MPI |
20 |
1920 |
5.8 |
9.5 |
Performance Analysis
Speed-Up Behavior
-
The performance improves nearly linearly up to around 5 nodes, achieving a 4.6× speed-up over the single-node SMP run.
-
Beyond 5 nodes, speed-up continues to increase, reaching 9.5× with 20 nodes (1920 cores).
-
The curve indicates diminishing returns at higher node counts, typical for communication-bound workloads.
The following plot shows the scaling behavior:
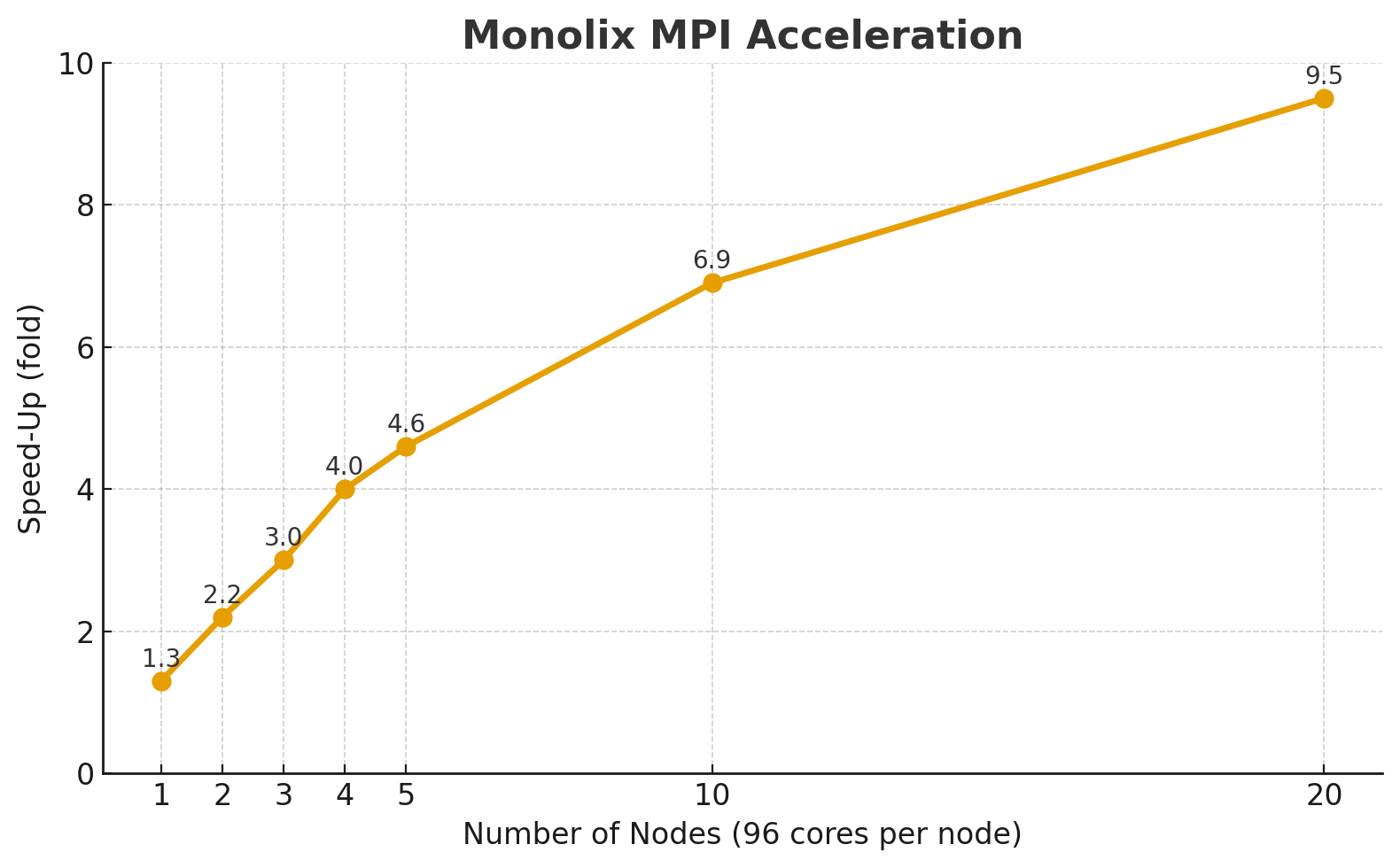
The trend reflects a strong scaling regime where computational work is distributed effectively but inter-node communication gradually becomes the dominant factor.
Efficiency Calculation
Parallel efficiency is defined as:
|
# of Nodes |
Speed-up |
Efficiency (%) |
|---|---|---|
|
1 |
1.3 |
130 %* |
|
2 |
2.2 |
110 %* |
|
3 |
3.0 |
100 % |
|
4 |
4.0 |
100 % |
|
5 |
4.6 |
92 % |
|
10 |
6.9 |
69 % |
|
20 |
9.5 |
48 % |
* Values > 100 % at small scale reflect measurement noise and cache effects rather than true superlinear scaling.
Interpretation
-
Up to 4 nodes, MPI scales almost perfectly (≈ 100 % efficiency).
-
Between 5 – 10 nodes, efficiency drops moderately due to increased communication overhead.
-
At 20 nodes, performance remains strong but efficiency decreases to ~50 %, which is typical for distributed workloads with high synchronization needs.
Best Practices for MPI Execution
-
Use sufficient problem size:
The computational load per core should be high enough to offset communication costs. -
Monitor scaling efficiency:
Efficiency <70% typically signals that further node scaling is not cost-effective.
Conclusion
MPI parallelization in MonolixSuite offers near-linear speed-up up to 4–5 nodes and substantial performance gains up to 20 nodes.
For large QSP simulations, this enables reducing multi-hour runs to just a few minutes, making high-throughput parameter estimation and simulation studies practical on modern HPC clusters.