
In Monolix, a dataset should be loaded in the Data tab to create a project. To be accepted in the Data tab, the dataset should be in a specific format described below. If your dataset is not in the right format, in most cases, it is possible to format it in a few steps in the data formatting tab, to incorporate the missing information. Once the dataset is accepted and once a model is loaded, it is possible to filter the dataset to remove outliers or focus on a particular group. The data set format used in Monolix is the same as for the entire MonolixSuite, to allow smooth transitions between applications. In this format:
-
Each line corresponds to one individual and one time point.
-
Each line can include a single measurement (also called observation), or a dose amount (or both a measurement and a dose amount).
-
Dosing information should be indicated for each individual in a specific column, even if it is the same treatment for all individuals.
-
Headers are free but there can be only one header line.
-
Different types of information (dose, observation, covariate, etc) are recorded in different columns, which must be tagged with a column type (see below).
The column types are very similar and compatible with the structure used by the NONMEM software (the differences are listed here). This is specified when the user defines each column type in the data set as in the following picture.
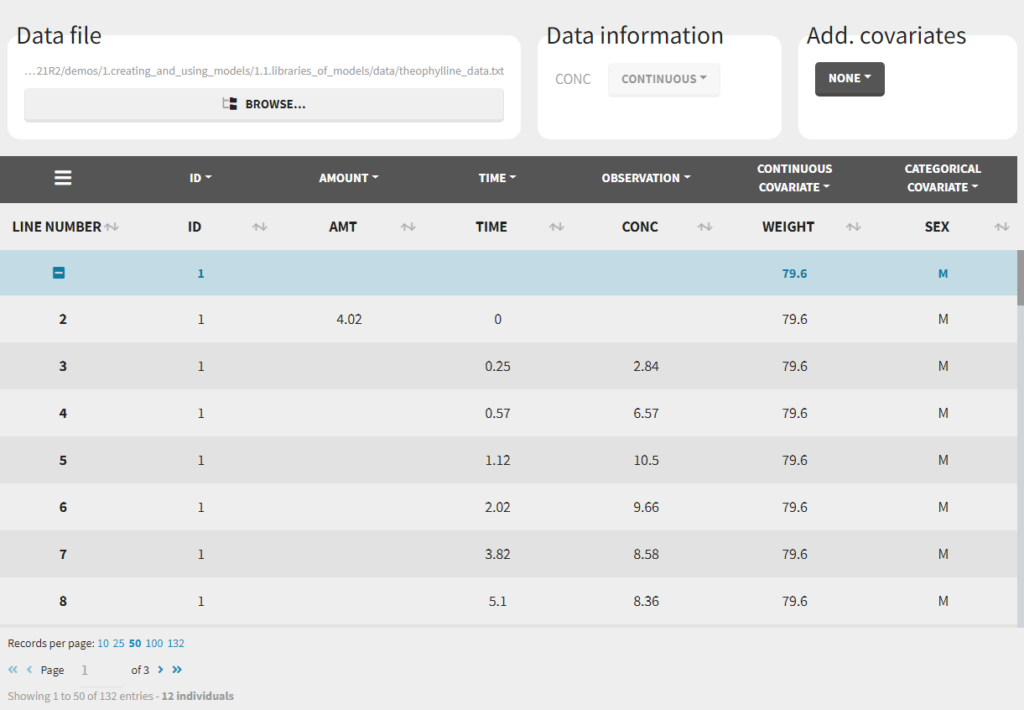
Notice that Monolix often provides an initial guess of the type of the column depending on the name.
Description of all possible column types
Column-types used for all types of lines:
-
ID (mandatory): identifier of the individual
-
OCCASION (formerly OCC): identifier (index) of the occasion
-
TIME (mandatory): time of the dose or observation record
-
NOMINAL TIME (from 2024 version): time at which doses and observations were expected to occur
-
DATE/DAT1/DAT2/DAT3: date of the dose or observation record, to be used in combination with the TIME column
-
EVENT ID (formerly EVID): identifier to indicate if the line is a dose-line or a response-line
-
IGNORED OBSERVATION (formerly MDV): identifier to ignore the OBSERVATION information of that line
-
IGNORED LINE (from 2019 version): identifier to ignore all the informations of that line
-
CONTINUOUS COVARIATE (formerly COV): continuous covariates (which can take values on a continuous scale)
-
CATEGORICAL COVARIATE (formerly CAT): categorical covariate (which can only take a finite number of values)
-
REGRESSOR (formerly X): defines a regression variable, i.e a variable that can be used in the structural model (used e.g for time-varying covariates)
-
IGNORE: ignores the information of that column for all lines
Column-types used for response-lines:
-
OBSERVATION (mandatory, formerly Y): records the measurement/observation for continuous, count, categorical or time-to-event data
-
OBSERVATION ID (formerly YTYPE): identifier for the observation type (to distinguish different types of observations, e.g PK and PD)
-
CENSORING (formerly CENS): marks censored data, below the lower limit or above the upper limit of quantification
-
LIMIT: upper or lower boundary for the censoring interval in case of CENSORING column
Column-types used for dose-lines:
-
AMOUNT (mandatory, formerly AMT): dose amount (with version 2024 only mandatory if dataset contains STEADY STATE, ADDITIONAL DOSES, INFUSIONRATE or INFUSION DURATION columns)
-
ADMINISTRATION ID (formerly ADM): identifier for the type of dose (given via different routes for instance)
-
INFUSION RATE (formerly RATE): rate of the dose administration (used in particular for infusions)
-
INFUSION DURATION (formerly TINF): duration of the dose administration (used in particular for infusions)
-
ADDITIONAL DOSES (formerly ADDL): number of doses to add in addition to the defined dose, at intervals INTERDOSE INTERVAL
-
INTERDOSE INTERVAL (formerly II): interdose interval for doses added using ADDITIONAL DOSES or STEADY-STATE column types
-
STEADY STATE (formerly SS): marks that steady-state has been achieved, and will add a predefined number of doses before the actual dose, at interval INTERDOSE INTERVAL, in order to achieve steady-state
Order of events
There are prioritization rules in place in case of various event types occurring at the same time. The order of row numbers in the data set is not important, and same is true for the order of administration and empty/reset macros in model files. The sequence of events will always be the following:
-
regressors are updated,
-
reset done by EVID=3 or EVID=4 is performed,
-
dose is administered,
-
empty/reset done by macros is performed,
-
observation is made.