
ID: subject identifier
The column is used to identify the different subjects and is mandatory. Its content is totally free (integers, double, strings…), but we recommend to use integers for better readability. The IDs will be sorted by order of appearance in the data set.
Examples
-
Example with strings: the string ‘.’ will not be interpreted as a repetition of the previous line. As a consequence a data set of the form
ID * *
John * *
John * *
Mike * *
. * *
contains 3 different subjects : ‘John’, ‘Mike’ and ‘.’.
-
Example with mixed IDs: the lines corresponding to the same subject do not need to be next to each other. Thus, the following file contains 2 subjects with IDs “1” and “2”.
ID * *
1 * *
1 * *
2 * *
2 * *
1 * *
Format restrictions
-
A data set shall contain one and only one column ID.
-
The ID must be defined for all lines.
-
The string ‘.’ will not be interpreted as a repetition of the previous line
OCCASION (formerly OCC): occasion identifiers
Occasions define different periods of time within individuals. Occasions may be (but don’t have to) used to define inter-occasion (intra-patient) variability. The MonolixSuite allows the definition of several columns with the column-type OCCASION, which can be used to define several levels of inter-occasion variability. The OCCASION columns can contain only integers (neither necessarily starting at one, nor necessarily consecutive), which represent occasion identifiers. All times points belonging to one occasion must be in one block (i.e not interrupted by time points of another occasion). When switching from one occasion to the next one, time can restart at the initial value or continue. If different occasions contain time points that overlap, a washout will automatically be added.
Examples and typical situations
-
Cross over study: In that case, data are collected for each patient during two independent treatment periods of time, there is an overlap on the time definition of the periods (e.g both periods start at 0). A column-type OCCASION can be used used to identify the periods. See here for an example.
-
Occasions with washout (due to EVENT ID = 4): In that case, there are no overlap between the periods. The time is increasing but the dynamical system (i.e. the compartments) is reset when the second period starts. In particular,
EVENT ID = 4indicates that the system is reset (washout) for example, when a new dose is administrated. See here for an example. -
Occasions with washout (due to overlapping times): In that case, the time is increasing and the overlap between two time points of two different occasions creates a washout. If the washout is not desired, one of the two times can be offset by a small value to avoid the overlap.
-
Occasions without washout: In that case, there are no overlap between the periods. The time is increasing and we want to differentiate periods in terms of occasions without any reset of the dynamical system. On the example defined here, multiple doses are administrated to each patient and each period of time between successive doses is defined as a different occasion via the column-type OCCASION.

However, the following situation, which would aim at defining the same occasion index to all morning doses, is not allowed:
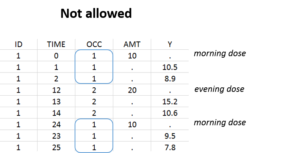
How can occasions appear while no OCCASION column is defined?
Occasions are automatically created if there is an EVENT ID column with a value 4, which is not the first record of the individual. Within an individual, each EVENT ID = 4 will create a new occasion. The automatically created occasion column is called OCCevid and will be visible in the Statistical model & Tasks tab in Monolix interface. The data set file itself is not modified (the OCCevid column is internal in Monolix). The OCCevid column is not created if an identical OCCASION column is already present. Inter-occasion variability can be considered for the automatically created OCCevid occasions but doesn’t has to.
The following data on the right has an EVID column (tagged as EVENT ID column-type) with a value of 4. This will automatically create an occasion column called OCCevid. The data set on the left is thus equivalent to the data set on the right:
|
|
|---|
FAQ on occasions in the data set
-
Do all the individual need to share the same sequence of occasion?
No, the number of occasions and the times defining the occasions can differ from one individual to another. -
Do the occasion indices need to start at one for each individual? No.
-
Do the occasion indices need to be consecutive for each individual? No.
-
Is there any limit in terms of number of occasions? No.
-
Is it possible to have several levels of occasions?
Yes, it is possible to have several level of occasions (multiple occasion columns).
Format restrictions
-
The OCCASION columns should contain only integers.
-
If the OCCASION column-type is used, the OCCASION must be defined for all lines.