
Objectives: learn how to define and use regression variables (time varying covariates).
Demos: reg1_project, reg2_project
Introduction
A regression variable is a variable x which is a given function of time, which is not defined in the model but which is used in the model. x is only defined at some time points
(possibly different from the observation time points), but x is a function of time that should be defined for any t (if is used in an ODE for instance, or if a prediction is computed on a fine grid). Then, Mlxtran defines the function x by interpolating the given values
. In the current version of Mlxtran, interpolation is performed by using the last given value:
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-3)'%3e%3cuse xlink:href='%23MJMATHI-78' x='0' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='572' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-74' x='962' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-29' x='1323' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-3D' x='1990' y='0'%3e%3c/use%3e%3cg transform='translate(3047%2c0)'%3e%3cuse xlink:href='%23MJMATHI-78' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='809' y='-213'%3e%3c/use%3e%3c/g%3e%3cg transform='translate(5511%2c0)'%3e%3cuse xlink:href='%23MJMAIN-66'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-6F' x='306' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-72' x='807' y='0'%3e%3c/use%3e%3c/g%3e%3cg transform='translate(7210%2c0)'%3e%3cuse xlink:href='%23MJMATHI-74' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='511' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2264' x='8241' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-74' x='9297' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-3C' x='9937' y='0'%3e%3c/use%3e%3cg transform='translate(10993%2c0)'%3e%3cuse xlink:href='%23MJMATHI-74' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(361%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2B' x='412' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-31' x='1191' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Or linearly:
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c54)'%3e%3cuse xlink:href='%23MJMATHI-78' x='0' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='572' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-74' x='962' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-29' x='1323' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-3D' x='1990' y='0'%3e%3c/use%3e%3cg transform='translate(3047%2c0)'%3e%3cuse xlink:href='%23MJMATHI-78' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='809' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='4233' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='5234' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-74' x='5623' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2212' x='6207' y='0'%3e%3c/use%3e%3cg transform='translate(7208%2c0)'%3e%3cuse xlink:href='%23MJMATHI-74' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='511' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='7961' y='0'%3e%3c/use%3e%3cg transform='translate(8350%2c0)'%3e%3cg transform='translate(120%2c0)'%3e%3crect stroke='none' width='4175' height='60' x='0' y='220'%3e%3c/rect%3e%3cg transform='translate(60%2c788)'%3e%3cuse xlink:href='%23MJMATHI-78' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(572%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2B' x='412' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-31' x='1191' y='0'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2212' x='2090' y='0'%3e%3c/use%3e%3cg transform='translate(3091%2c0)'%3e%3cuse xlink:href='%23MJMATHI-78' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='809' y='-213'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cg transform='translate(271%2c-686)'%3e%3cuse xlink:href='%23MJMATHI-74' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(361%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2B' x='412' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-31' x='1191' y='0'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2212' x='1879' y='0'%3e%3c/use%3e%3cg transform='translate(2880%2c0)'%3e%3cuse xlink:href='%23MJMATHI-74' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='511' y='-213'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg transform='translate(14266%2c0)'%3e%3cuse xlink:href='%23MJMAIN-66'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-6F' x='306' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-72' x='807' y='0'%3e%3c/use%3e%3c/g%3e%3cg transform='translate(15966%2c0)'%3e%3cuse xlink:href='%23MJMATHI-74' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='511' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2264' x='16996' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-74' x='18053' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-3C' x='18692' y='0'%3e%3c/use%3e%3cg transform='translate(19748%2c0)'%3e%3cuse xlink:href='%23MJMATHI-74' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(361%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2B' x='412' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-31' x='1191' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Regressor definition in a data set
It is possible to have in a data set one or several columns with column-type REGRESSOR. Within a given subject-occasion, string “.” will be interpolated (last value carried forward interpolation is used) for observation and dose-lines. Lines with no observation and no dose but with regressor values are also taken into account by Monolix for regressor interpolation.
Several points have to be noticed:
-
The name of the regressor in the data set and the name of the regressor used in the longitudinal model do not need to be identical.
-
If there are several regressors, the mapping will be done by order of definition.
-
Regressors can only be used in the longitudinal model.
Continuous regression variables
-
reg1_project (data = reg1_data.txt , model=reg1_model.txt)
We consider a basic PD model in this example, where some concentration values are used as a regression
variable. The data set is defined as follows
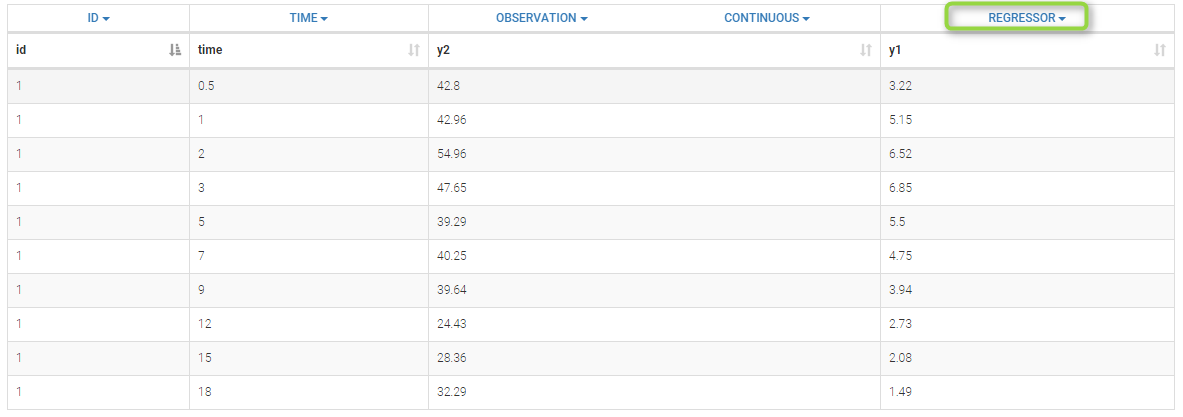
[LONGITUDINAL]
input = {Emax, EC50, Cc}
Cc = {use=regressor}
EQUATION:
E = Emax*Cc/(EC50 + Cc)
OUTPUT:
output = E
As explained in the previous subsection, there is no name correspondance between the regressor in the data set and the regressor in the model file. Thus, in that case, the values of Cc with respect to time will be taken from the y1 column.
In addition, in that case, the predicted effect is therefore piece wise constant because
-
the regressor interpolation is performed by using the last given value, and then Cc is piece wise constant.
-
The effect model is direct with respect to the concentration.
Thus, it changes at the time points where concentration values are provided:
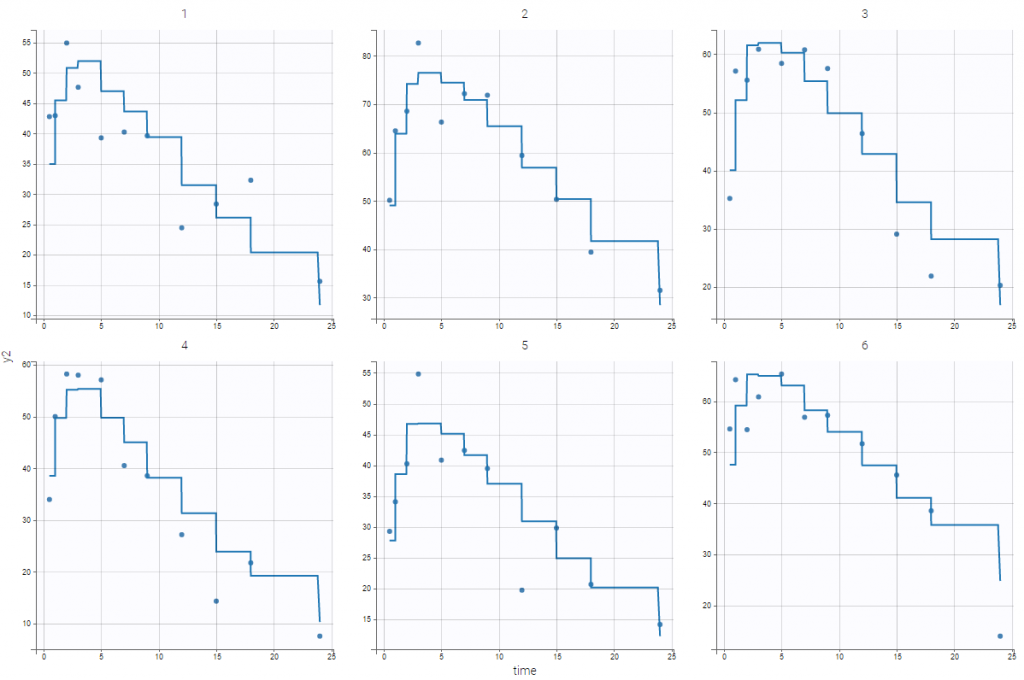
Categorical regression variables
-
reg2_project (data = reg2_data.txt , model=reg2_model.txt)
The variable
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-3)'%3e%3cuse xlink:href='%23MJMATHI-7A' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(465%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='345' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) takes its values in {1, 2} in this example and represents the state of individual i at time
takes its values in {1, 2} in this example and represents the state of individual i at time
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-3)'%3e%3cuse xlink:href='%23MJMATHI-74' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(361%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='345' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) . We then assume that the observed data
. We then assume that the observed data
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-3)'%3e%3cuse xlink:href='%23MJMATHI-79' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(490%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='345' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) has a Poisson distribution with parameter lambda1 if
has a Poisson distribution with parameter lambda1 if
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-3)'%3e%3cuse xlink:href='%23MJMATHI-7A' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(465%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='345' y='0'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-3D' x='1379' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-31' x='2435' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) and parameter lambda2 if
and parameter lambda2 if
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-3)'%3e%3cuse xlink:href='%23MJMATHI-7A' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(465%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='345' y='0'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-3D' x='1379' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-32' x='2435' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) . z is known in this example: it is then defined as a regression variable in the model:
. z is known in this example: it is then defined as a regression variable in the model:
[LONGITUDINAL]
input = {lambda1, lambda2, z}
z = {use=regressor}
EQUATION:
if z==0
lambda=lambda1
else
lambda=lambda2
end
DEFINITION:
y = {type=count,
log(P(y=k)) = -lambda + k*log(lambda) - factln(k)
}
OUTPUT:
output = y