
Related resources on modeling categorical data in Monolix:
-
Columns used to define observations: formatting of categorical data in the MonolixSuite.
-
Categorical observation model : details on the different models for categorical data that can be used in Monolix and their syntax.
On the current page, we show examples of categorical data models from the Monolix demos.
Demos: categorical1_project, categorical2_project, markov0_project, markov1a_project, markov1b_project, markov1c_project, markov2_project, markov3a_project, markov3b_project
Ordered categorical data
-
categorical1_project (data = ‘categorical1_data.txt’, model = ‘categorical1_model.txt’)
In this example, observations are ordinal data that take their values in {0, 1, 2, 3}:
-
Cumulative odds ratio are used in this example to define the model
where
This model is implemented in categorical1_model.txt:
[LONGITUDINAL]
input = {th1, th2, th3}
DEFINITION:
level = { type = categorical, categories = {0, 1, 2, 3},
logit(P(level<=0)) = th1
logit(P(level<=1)) = th1 + th2
logit(P(level<=2)) = th1 + th2 + th3
}
A normal distribution is used for
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-50)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-31' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) , while log-normal distributions for
, while log-normal distributions for
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-50)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) and
and
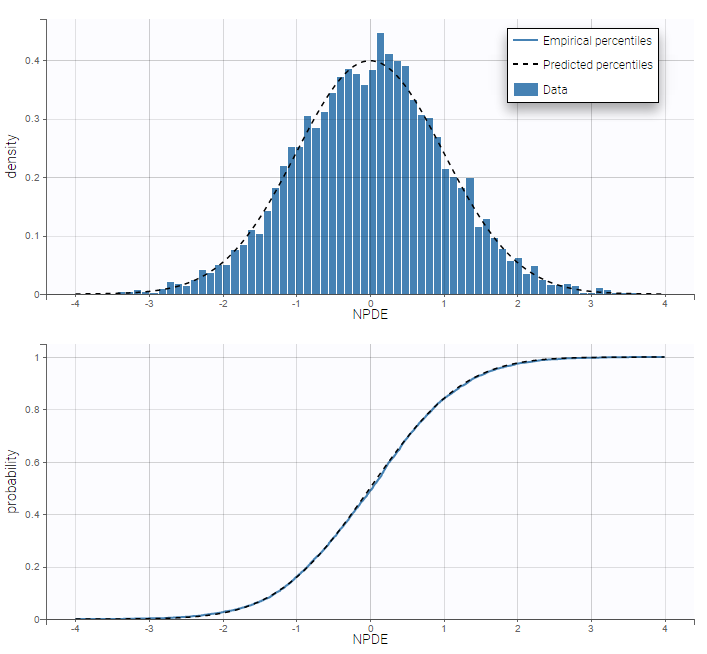
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-50)'%3e%3cuse xlink:href='%23MJMATHI-3B8' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-33' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) ensure that these parameters are positive (even without variability). Residuals for noncontinuous data reduce to NPDEs. We can compare the empirical distribution of the NPDEs with the distribution of a standardized normal distribution:
ensure that these parameters are positive (even without variability). Residuals for noncontinuous data reduce to NPDEs. We can compare the empirical distribution of the NPDEs with the distribution of a standardized normal distribution:
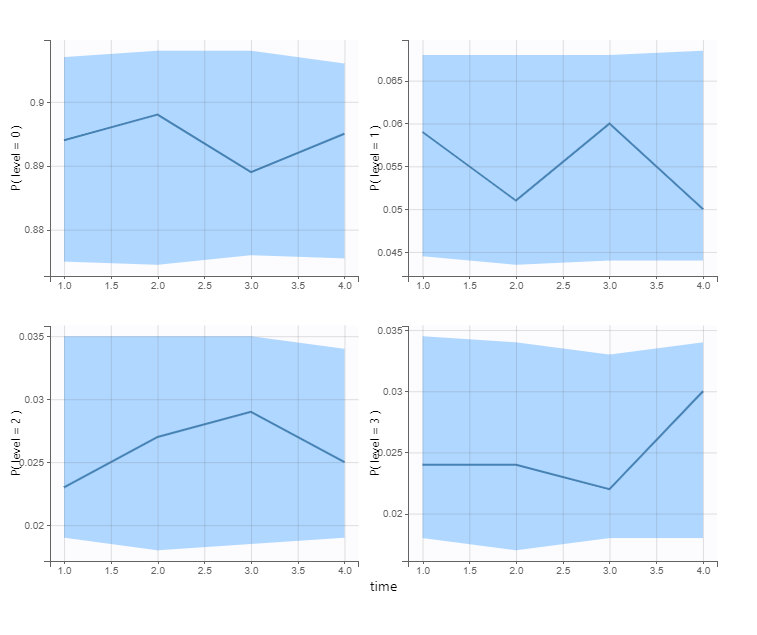
VPC’s for categorical data compare the observed and predicted frequencies of each category over time:
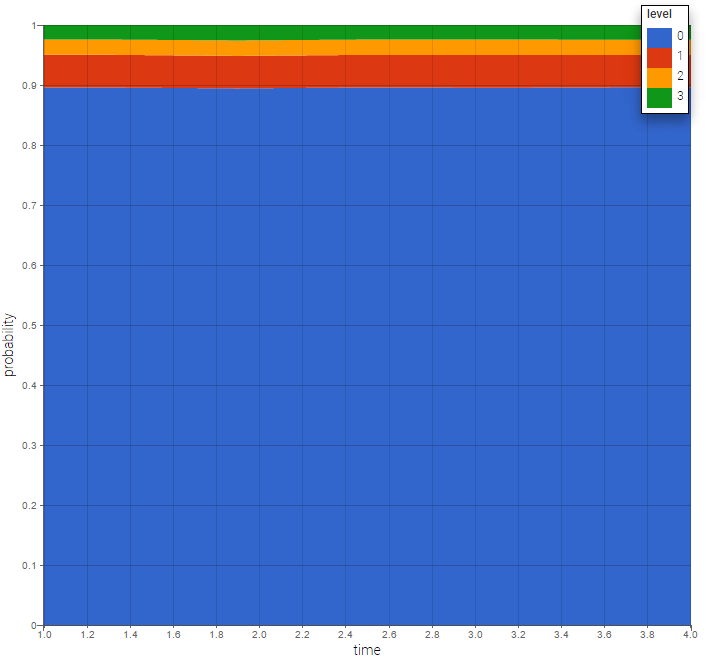
The prediction distribution can also be computed by Monte-Carlo:
Logistic regression
Logistic regression is a subcase of categorical data where the data can take only two different values such as yes/no or responder/non-responder. The values in the OBSERVATION column must be encoded as 0 and 1, and the probability of the observation to be 1 is defined in the model. This probability can vary over time and can depend on predictors (i.e covariates). A complete example in shown in the video below.
Ordered categorical data with regression variables
-
categorical2_project (data = ‘categorical2_data.txt’, model = ‘categorical2_model.txt’)
A proportional odds model is used in this example, where PERIOD and DOSE are used as regression variables (i.e. time-varying covariates).
Discrete-time Markov chain
If observation times are regularly spaced (constant length of time between successive observations), we can consider the observations
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-3)'%3e%3cuse xlink:href='%23MJMAIN-28' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(389%2c0)'%3e%3cuse xlink:href='%23MJMATHI-79' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(490%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='345' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2C' x='1515' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6A' x='1961' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-3D' x='2651' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-31' x='3707' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2C' x='4208' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-32' x='4653' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2C' x='5153' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2026' x='5599' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2C' x='6938' y='0'%3e%3c/use%3e%3cg transform='translate(7383%2c0)'%3e%3cuse xlink:href='%23MJMATHI-6E' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='849' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='8328' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) to be a discrete-time Markov chain.
to be a discrete-time Markov chain.
-
markov0_project (data = ‘markov1a_data.txt’, model = ‘markov0_model.txt’)
In this project, states are assumed to be independent and identically distributed:
Observations in markov1a_data.txt take their values in {1, 2}.
-
markov1a_project (data = ‘markov1a_data.txt’, model = ‘markov1a_model.txt’)
Here,
[LONGITUDINAL]
input = {p11, p21}
DEFINITION:
State = {type = categorical, categories = {1,2}, dependence = Markov
P(State=1|State_p=1) = p11
P(State=1|State_p=2) = p21
}
The distribution of the initial state is not defined in the model, which means that, by default,
-
markov1b_project (data = ‘markov1b_data.txt’, model = ‘markov1b_model.txt’)
The distribution of the initial state,
, is estimated in this example
DEFINITION:
State = {type = categorical, categories = {1,2}, dependence = Markov
P(State_1=1)= p
P(State=1|State_p=1) = p11
P(State=1|State_p=2) = p21
}
-
markov3a_project (data = ‘markov3a_data.txt’, model = ‘markov3a_model.txt’)
Transition probabilities change with time in this example. We then define time varying transition probabilities in the model:
[LONGITUDINAL]
input = {a1, b1, a2, b2}
EQUATION:
lp11 = a1 + b1*t/100
lp21 = a2 + b2*t/100
DEFINITION:
State = {type = categorical, categories = {1,2}, dependence = Markov
logit(P(State=1|State_p=1)) = lp11
logit(P(State=1|State_p=2)) = lp21
}
-
markov2_project (data = ‘markov2_data.txt’, model = ‘markov2_model.txt’)
Observations in markov2_data.txt take their values in {1, 2, 3}. Then, 6 transition probabilities need to be defined in the model.
[LONGITUDINAL]
input = {a11, a12, a21, a22, a31, a32}
DEFINITION:
State = {type = categorical, categories = {1,2,3}, dependence = Markov
logit(P(State<=1|State_p=1)) = a11
logit(P(State<=2|State_p=1)) = a11+a12
logit(P(State<=1|State_p=2)) = a21
logit(P(State<=2|State_p=2)) = a21+a22
logit(P(State<=1|State_p=3)) = a31
logit(P(State<=2|State_p=3)) = a31+a32
}
OUTPUT:
output=State
Continuous-time Markov chain
The previous situation can be extended to the case where time intervals between observations are irregular by modeling the sequence of states as a continuous-time Markov process. The difference is that rather than transitioning to a new (or the same) state at each time step, the system remains in the current state for some random amount of time before transitioning. This process is now characterized by transition rates
from the state
to the state
.
-
markov1c_project (data = ‘markov1c_data.txt’, model = ‘markov1c_model.txt’)
Observation times are irregular in this example. Then, a continuous time Markov chain should be used in order to take into account the Markovian dependence of the data:
DEFINITION:
State = { type = categorical, categories = {1,2}, dependence = Markov
transitionRate(1,2) = q12
transitionRate(2,1) = q21
}
-
markov3b_project (data = ‘markov3b_data.txt’, model = ‘markov3b_model.txt’)
Time varying transition rates are used in this example.
[LONGITUDINAL]
input = {c1, d1, c2, d2}
EQUATION:
q12 = max(0.001, c1 + d1*t/100)
q21 = max(0.001, c2 + d2*t/100)
DEFINITION:
State = {type = categorical, categories = {1,2}, dependence = Markov
transitionRate(1,2) = q12
transitionRate(2,1) = q21
}
OUTPUT:
output=State
-
Initial state: by default, the probabilies for the initial state (first observation) are equal for all categories. For instance in case of 3 categories,
.
To define different initial probabilities (e.g all individuals in State 1), they can be defined using the following syntax. Note that it is only necessary to define the probabilities of N-1 categories (as the last one can be derived from the sum being equal to 1).[LONGITUDINAL] input = {c1, d1, c2, d2} EQUATION: q12 = max(0.001, c1 + d1*t/100) q21 = max(0.001, c2 + d2*t/100) DEFINITION: State = {type = categorical, categories = {1,2}, dependence = Markov P(State_1=1)= 1 transitionRate(1,2) = q12 transitionRate(2,1) = q21 } OUTPUT: output=State