
Details on the different types of models for count data that can be used in Simulx and their syntax are given here: Count observation model Smlx and a detailed description of the library of count models integrated within Simulx is given here: Count data model library .
On the current page, we show an example from the Simulx demos and explain the format of simulated count data.
Count data with time-varying distribution
-
7.3.count/count.smlx (model = ‘Verhulst_model.txt’)
In this demo, we observe the number of correct answers to a questionnaire of 30 questions. The probability of giving a correct answer is decreasing over time, due to the disease progression. No random effect is considered on the parameters of the model.
[LONGITUDINAL]
input={p0, alpha}
EQUATION:
; maximum value of correct answers = number of questions = number of experiments
n = 30
; probability of success => decreases over time
p = p0 /((p0 + (1-p0)*exp(alpha*t)))
DEFINITION:
; binomial distribution of n trials and probability of succes p
nbCorrectAnswers = {type=count, log(P(nbCorrectAnswers=k))= factln(n)-factln(k)-factln(n-k) + k*log(p) + (n-k)*log(1-p)}
OUTPUT:
output = nbCorrectAnswers
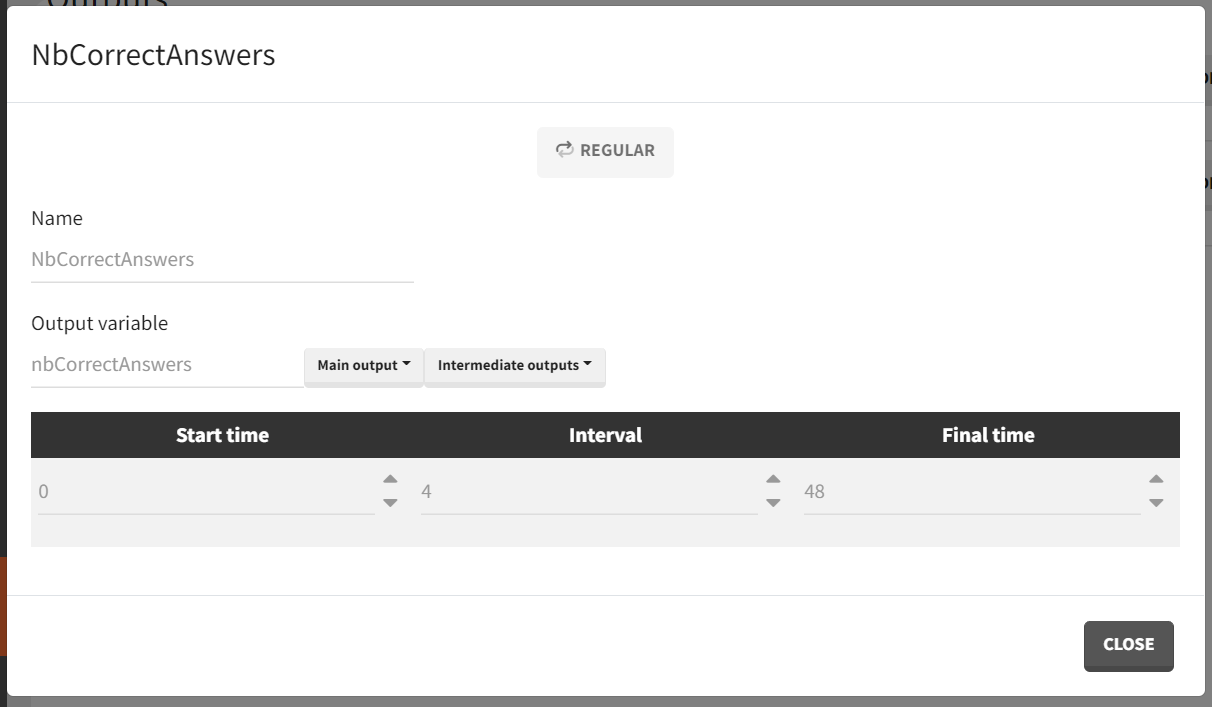
The output element "NbCorrectAnswers" records the value of nbCorrectAnswers every 4 weeks:
This output element can be used in Simulation but not in Exploration, because the model variable nbCorrectAnswers is a random variable.
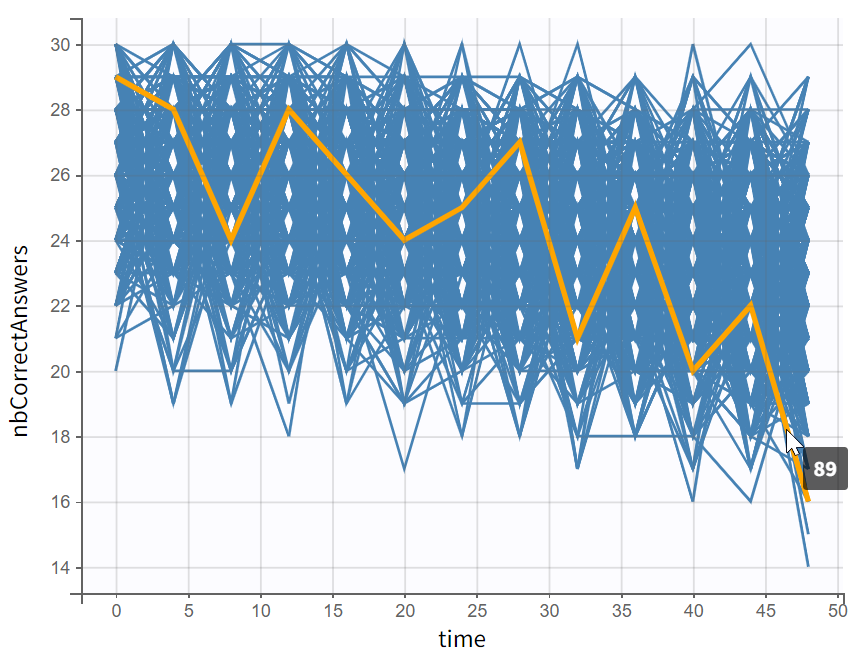
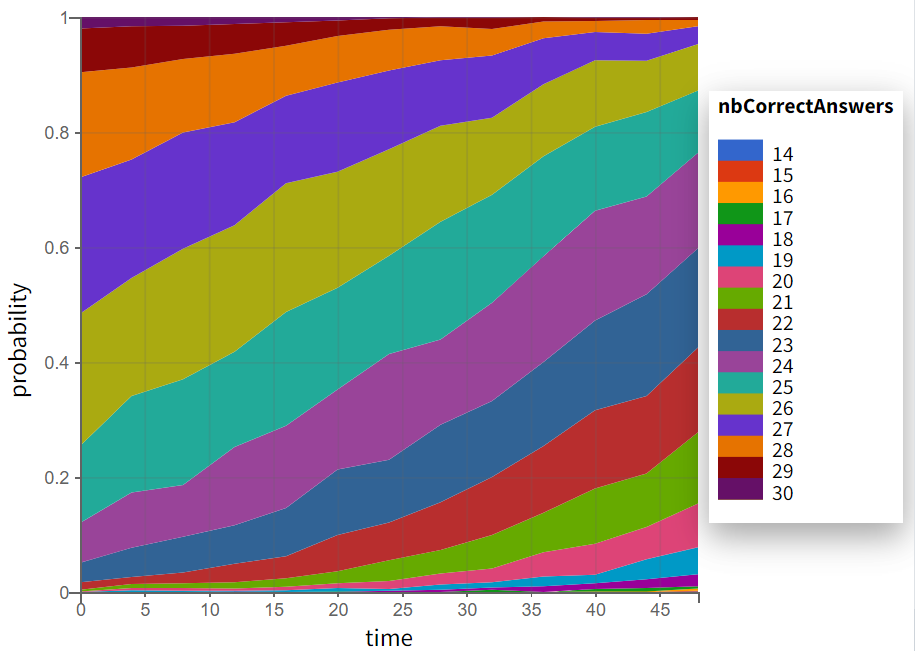
The model is simulated over 1000 individuals. The resulting simulations can be visualized as continuous curves in the Individual output plot (left) and as probabilities for the different values in the Output distribution plot (right):
|
|
Formatting of count data in the MonolixSuite
After simulating a count model, it is possible to export the simulated data from Simulx. This section describes the standard format for count data in the MonolixSuite.
Count data can take only non-negative integer values that come from counting something, e.g., the number of trials required for completing a given task. The task can for instance be repeated several times and the individuals performance followed.
Count data can also represent the number of events happening in regularly spaced intervals, e.g the number of seizures every week. If the time intervals are not regular, the data may be considered as repeated time-to-event interval censored, or the interval length can be given as regressor to be used to define the probability distribution in the model.
Examples
-
Basic example: in the data set below, 10 trials are necessary the first day (t=0), 6 the second day (t=24), etc.
ID TIME Y
1 0 10
1 24 6
1 48 5
1 72 2
One can see the epilepsy attacks data set from the Monolix documentation for a more practical example.