[PKanalix] Generate NCA individual fits (lambda_z regression)
Plot the NCA individual fits (LambdaZ regression).
Usage
plotNCAIndividualFits(
settings = list(),
preferences = list(),
stratify = list()
)
Arguments
settings List with the following settings:obsDots (logical) - If TRUE individual observations are displayed as dots (default TRUE). obsLines (logical) - If TRUE individual observations are displayed as lines (default FALSE). cens (logical) - If TRUE censored observations are displayed as dots (default TRUE). obsUnused (logical) - If TRUE (and if dots is set to TRUE), individual observations not used for lambda z calculation are displayed as dots (default TRUE). obsUnusedColor - If obsUnused is TRUE, observation points not included in lambda_z regression can be colored with the same color as used for the points included in lambda_z ("colored"), or can be colored in grey ("greyed", default). lambda_z (logical) - If TRUE, lambda_z regression lines are displayed (default TRUE). dosingTimes (logical) - If TRUE, dosing times are displayed as vertical lines (default FALSE). splitOccasions (logical) - If TRUE, occasions are displayed on separate subplots (default TRUE). If FALSE, all occasions are overlaid on the same subplot. legend (logical) If TRUE, plot legend is displayed (default FALSE). grid (logical) If TRUE, plot grid is displayed (default TRUE). xlog (logical) If TRUE, log-scale on x axis is used (default FALSE). ylog (logical) If TRUE, log-scale on y axis is used (default TRUE). xlab (character) label on x axis (default "time"). ylab (character) label on y axis (default "concentration"). ncol (integer) number of columns to arrange the subplots (default 4). xlim (c(double, double)) limits of the x axis. ylim (c(double, double)) limits of the y axis. fontsize (integer) Font size of text elements (default 11). units (logical) If TRUE, units are added in axis labels (default TRUE). scales (character) Should scales be fixed ("fixed"), free ("free", the default), or free in one dimension ("free_x", "free_y"). preferences (optional) preferences for plot display, run getPlotPreferences("plotNCAIndividualFits") to check available options. stratify List with the stratification arguments. Stratification is not available in case "sparse data" calculations are used.groups - Definition of stratification groups. By default, stratification groups are already defined as one group for each category for categorical covariates and occasions, and two groups of equal number of individuals for continuous covariates. To redefine groups, for each covariate to redefine, specify a list with:name(character)covariate name (e.g "AGE")definition(vector(continuous) || list>(categorical))For continuous covariates, vector of break values (e.g c(35, 65)). For categorical covariates, groups of categories as a list of vectors (e.g list(c("study101"), c("study201","study202"))) filter (list< list> >) - List of pairs containing a covariate name and the vector of indexes or categories (for categorical covariates) of the groups to keep (by default no filtering is applied). For instance, list("AGE",c(1,3)) to keep the individuals belonging to the first and third age group, according to the definition in groups. For instance, list("FORM","ref") using the category name for categorical covariates. color (vector) - Vector of covariates used for coloring (by default no coloring is applied). For instance c("FORM","AGE"). colors - Vector of colors to use when color argument is used. Takes precedence over colors defined in preferences. For instance c("#ebecf0","#cdced1","#97989c"). individualSelection - Ids to display (by default the 12 first ids are displayed) defined as:indices (vector) - Indices of the individuals to display (by default, the 12 first individuals are selected). If occasions are present, all occasions of the selected individuals will be displayed. Takes precedence over ids. For instance c(5,6,10,11). isRange (logical) - If TRUE, all individuals whose index is inside [min(indices), max[indices]] are selected (FALSE by default). Forced to FALSE if ids is defined. ids (vector) - Names of the individuals to display. If occasions are present, all occasions of the selected individuals will be displayed. For instance c("101-01","101-02","101-03"). If ids are integers, can also be c(1,3,6). Ignored if indices is defined.
Value
A ggplot object
See also
Examples
initializeLixoftConnectors(software = "pkanalix")
project <- file.path(getDemoPath(), "/2.case_studies/project_Theo_extravasc_SD.pkx")
loadProject(project)
runNCAEstimation()
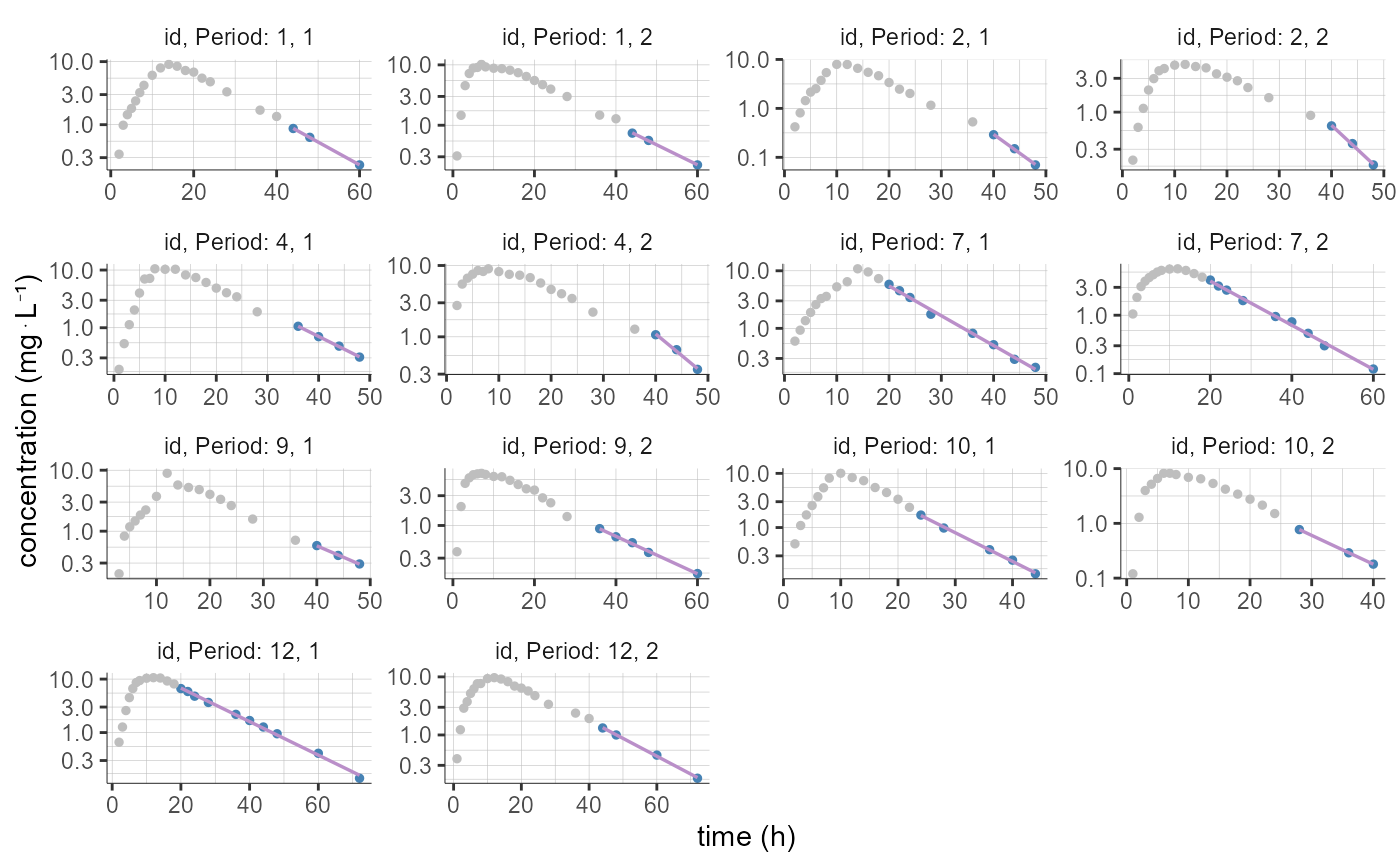
# by default 12 individuals are displayed (with 2 occasions each in this example)
plotNCAIndividualFits()
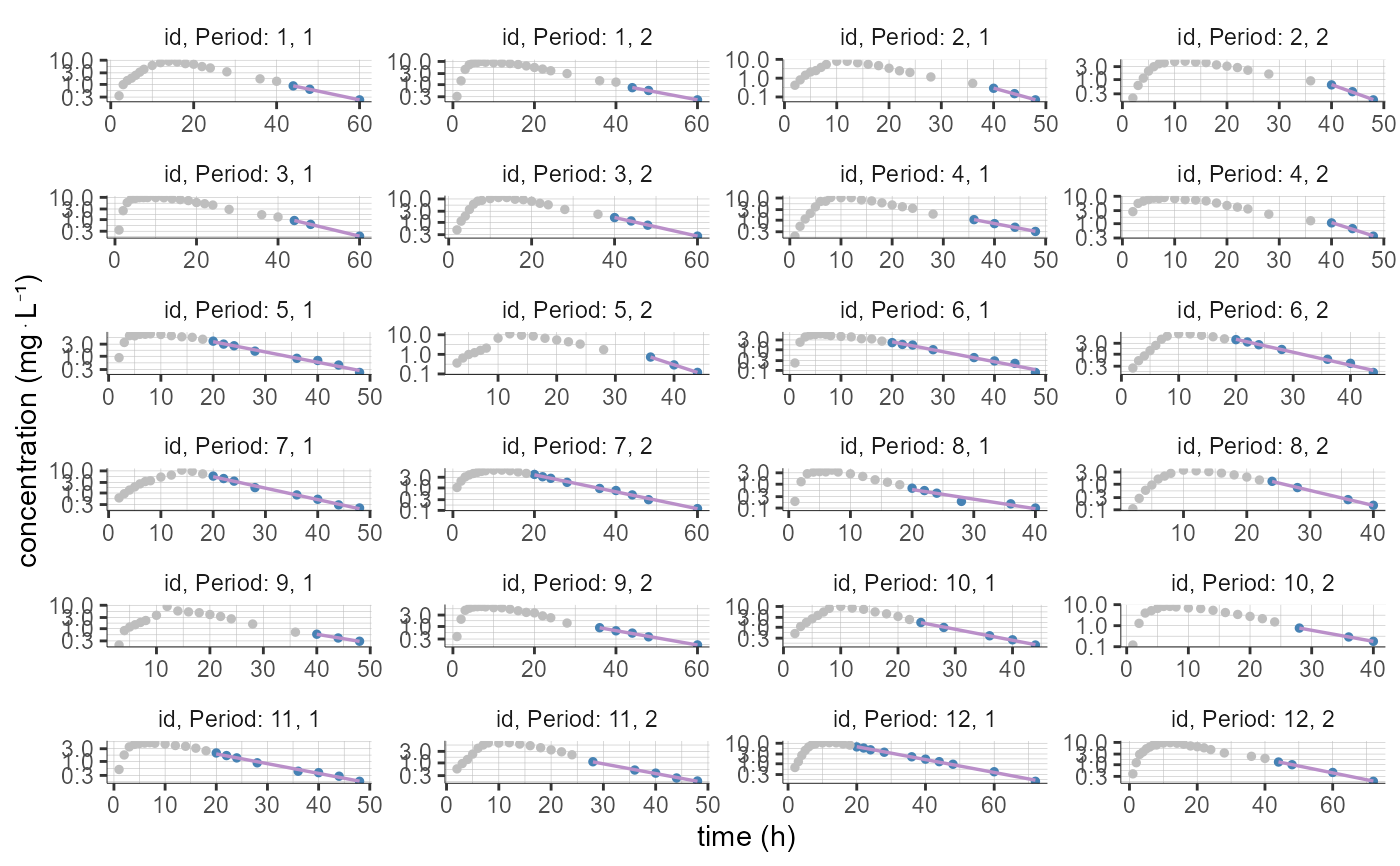
# loop to create several plots ("pages") with 6 individuals (2 occasions each) per page, using "indices" and "isRange"
nbIndiv <- 18
nbIndivPerPage <- 6
nbPages <- ceiling(nbIndiv/nbIndivPerPage)
for(i in 1:nbPages){
plotNCAIndividualFits(stratify = list(individualSelection=list(indices=c(nbIndivPerPage*(i-1)+1,nbIndivPerPage*i),
isRange=T)))
}
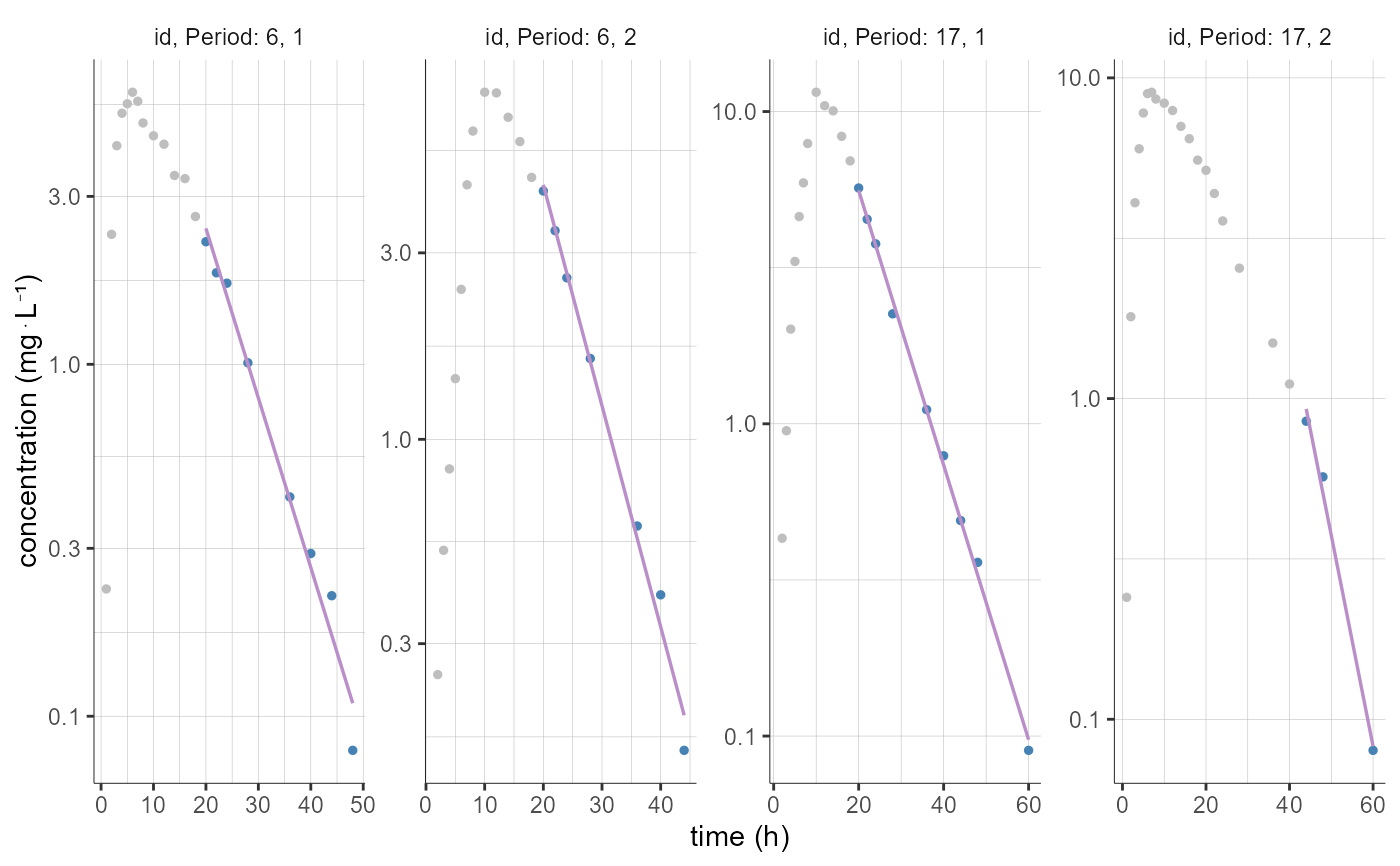
# selection of individuals based on id names
plotNCAIndividualFits(stratify = list(individualSelection=list(ids=c("6","17"))))
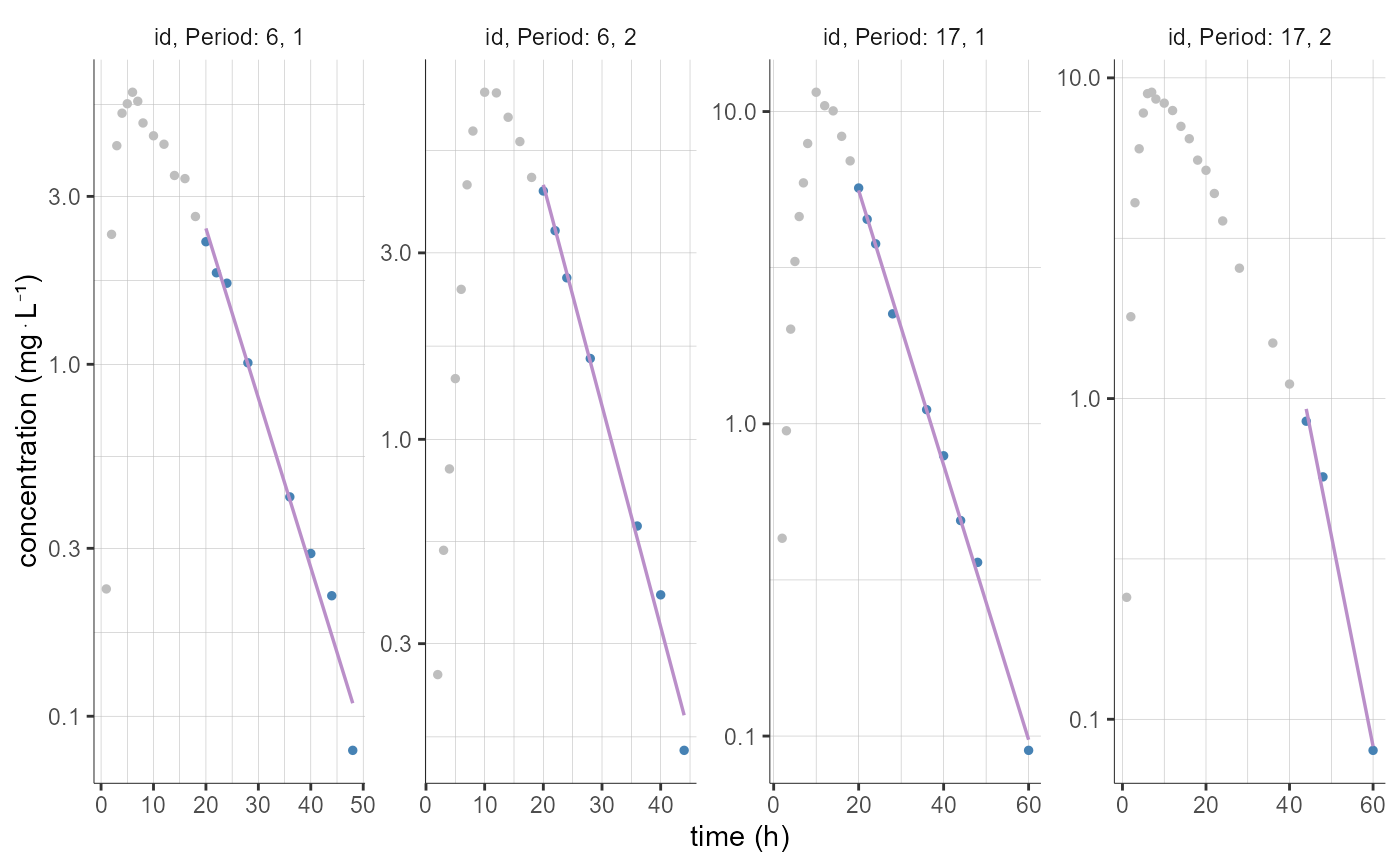
plotNCAIndividualFits(stratify = list(individualSelection=list(ids=c(6, 17))))
# plot only the observations (lambda_z=F) with dots, lines and dosing times. The two occasions are overlayed (splitOccasions=F)
# all observations are displayed in the same way without distinguishing those use for lambda_z (obsUnusedColor="colored")
# coloring by formulation with user-defined colors
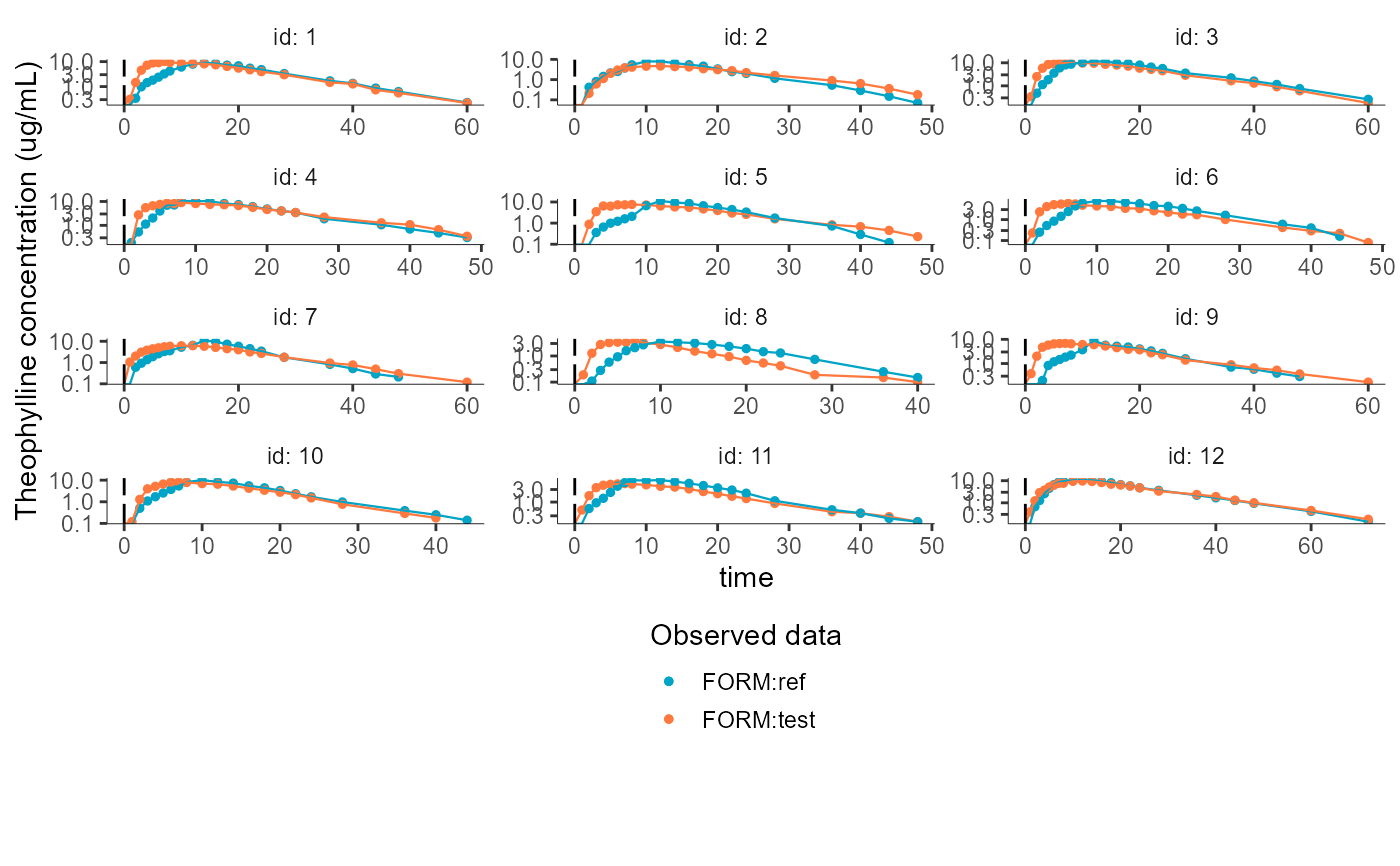
plotNCAIndividualFits(settings = list(lambda_z=F, obsDots=T, obsLines=T, dosingTimes=T,
splitOccasions=F, ncol=3, obsUnusedColor="colored",
legend=T, grid=F, ylog=T,
units=F, ylab="Theophylline concentration (ug/mL)"),
stratify = list(color=c("FORM"),
colors=c("#00a4c6","#ff793f")))
#> Warning: log-10 transformation introduced infinite values.
# get available preferences
getPlotPreferences("plotNCAIndividualFits")
#> $obs
#> $obs$color
#> [1] "#4682B4"
#>
#> $obs$radius
#> [1] 1
#>
#> $obs$shape
#> [1] 19
#>
#> $obs$lineWidth
#> [1] 0.4
#>
#> $obs$lineType
#> [1] "solid"
#>
#> $obs$legend
#> [1] "Observed data"
#>
#>
#> $censObs
#> $censObs$color
#> [1] "#D44242"
#>
#> $censObs$radius
#> [1] 1
#>
#> $censObs$shape
#> [1] 19
#>
#> $censObs$legend
#> [1] "Censored Data"
#>
#>
#> $obsUnused
#> $obsUnused$color
#> [1] "grey"
#>
#> $obsUnused$radius
#> [1] 1
#>
#> $obsUnused$shape
#> [1] 19
#>
#> $obsUnused$legend
#> [1] "Unused data"
#>
#>
#> $lambda_z
#> $lambda_z$color
#> [1] "#BA8FC9"
#>
#> $lambda_z$lineWidth
#> [1] 0.6
#>
#> $lambda_z$lineType
#> [1] "solid"
#>
#> $lambda_z$legend
#> [1] "LambdaZ regression"
#>
#>
#> $dosingTimes
#> $dosingTimes$color
#> [1] "#000000"
#>
#> $dosingTimes$lineWidth
#> [1] 0.5
#>
#> $dosingTimes$lineType
#> [1] "longdash"
#>
#> $dosingTimes$legend
#> [1] "Dosing times"
#>
#>
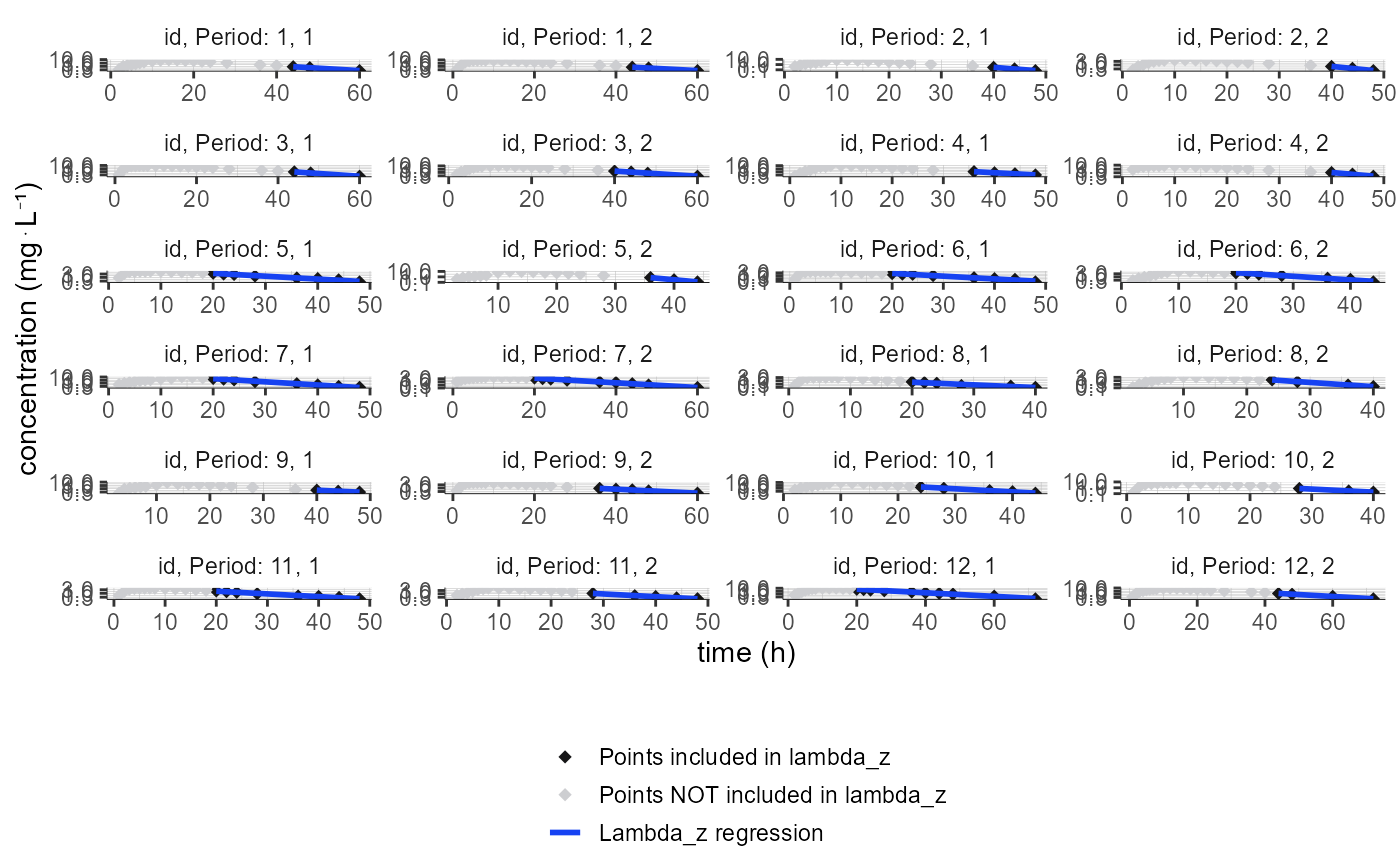
# change color, radius, shape, lineType, lineWidth and legend for all elements
plotNCAIndividualFits(settings = list(legend=T),
preferences = list(obs=list(color="#161617",
radius=2,
shape=18,
legend="Points included in lambda_z"),
censObs=list(color="#161617",
radius=2,
shape=5,
legend="BLQ points"),
obsUnused=list(color="#cdced1",
radius=2,
shape=18,
legend="Points NOT included in lambda_z"),
lambda_z=list(color="#1642f2",
lineWidth=1,
lineType="solid",
legend="Lambda_z regression")))
#==== stratification (not available for sparse data)
# define groups for AGE and color by AGE and FORM
plotNCAIndividualFits(settings = list(obsDots=T,legend=T,obsUnusedColor="colored", obsLines=T),
stratify = list(groups=list(name="AGE", definition=c(30, 35)),
color=c("AGE","FORM")))
#> Warning: log-10 transformation introduced infinite values.

# filter to keep only individuals with sequence "RT" (first among "RT" and "TR")
plotNCAIndividualFits(stratify = list(filter=list(list("SEQ","RT"))))
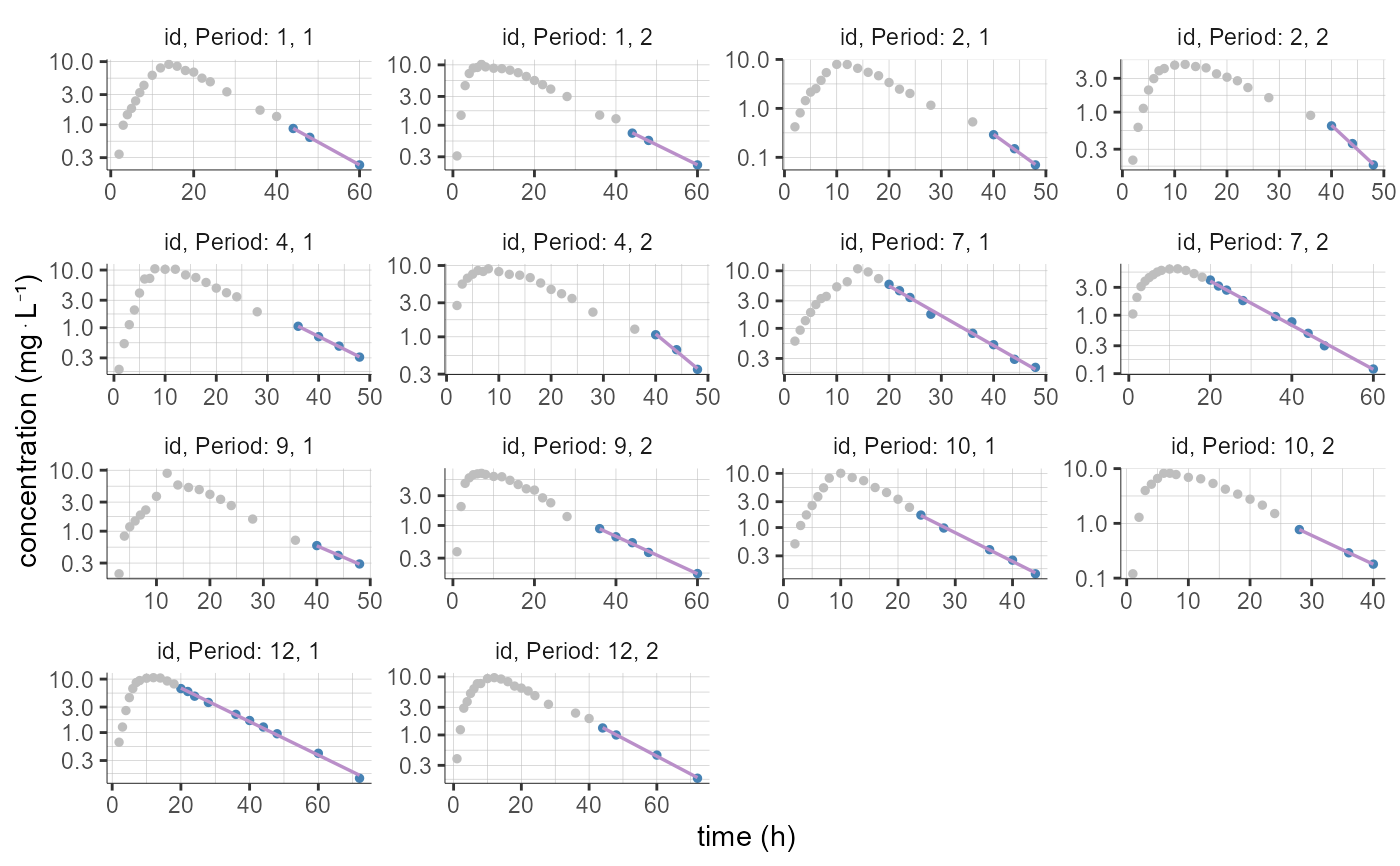
plotNCAIndividualFits(stratify = list(filter=list(list("SEQ",1))))