The following page describes all the settings that can be used in table placeholders in reporting templates. Placeholders for tables can include four different groups of settings. These are:
-
“data” (required) – containing settings about table content, such as type of the table, and rows and columns that the table will contain,
-
“display” (optional) – containing information about table display (e.g., number of significant digits to which the values in the table should be rounded, table direction, style, …
-
“stratification” (optional) – containing information about table splitting and/or filtering,
-
“renamings” (optional) – containing various words present in the data set or PKanalix that should be reworded in the table.
Settings inside these groups of settings need to be indented or put inside curly brackets. It is crucial to respect the indentation rules and the space after the “:” for the placeholder to be properly interpreted.
Data
Data settings define the type of the table that will be generated, as well as rows and columns that the table will contain. Here is the list of all settings of the data group of settings, along with their descriptions:
|
Setting |
Table |
Required
|
Possible values |
Description |
|
task |
All |
yes |
be, ca, nca |
Task of which the table represents the results. |
|
table |
Points included for lambdaZ (NCA)
|
yes |
pointsIncludedForLambdaZ, anova, coefficientsOfVariation, confidenceIntervals, cost |
Table type. If empty, CA or NCA parameters table will be generated (depending on the task argument). |
|
formulation |
Table of confidence intervals (BE) |
no (default: all) |
name of one of the test formulations present in the data set, or “all” |
In case of confidenceIntervals table and multiple test formulations, setting can be used to select one of the non-reference formulations. |
|
metrics |
Table of parameters (CA or NCA) |
no |
“all” or one or several of: ID, min, Q1, median, Q3, max, mean, SD, SE, CV, Ntot, Nobs, Nmiss, geoMean, geoSD, geoCV, harmMean |
If equal to “all”, all available rows or columns will be present in the table. If specific metrics are given, only those rows/columns will be available in the table. |
|
metrics |
Points included for lambdaZ (NCA) |
no |
“all” or one or several of: ID, time, concentration, BLQ, includedForLambdaZ |
If equal to “all”, all available rows or columns will be present in the table. If specific metrics are given, only those rows/columns will be available in the table. |
|
metrics |
Table of confidence intervals (BE) |
no |
“all” or one or several of: AdjustedMean, N, Difference, CIRawLower, CIRawUpper, Ratio, CILower, CIUpper, BE |
If equal to “all”, all available rows or columns will be present in the table. If specific metrics are given, only those rows/columns will be available in the table. |
|
metrics |
Coefficient of variation (BE) |
no |
“all” or one or several of: SD, CV |
If equal to “all”, all available rows or columns will be present in the table. If specific metrics are given, only those rows/columns will be available in the table. |
|
metrics |
Anova table (BE) |
no |
“all” or one or several of: DF, SUMSQ, MEANSQ, FVALUE, PR(>F) |
If equal to “all”, all available rows or columns will be present in the table. If specific metrics are given, only those rows/columns will be available in the table. |
|
metrics |
Cost table (CA) |
no |
“all” or one or several of: Cost, -2LL, AIC, BIC |
If equal to “all”, all available rows or columns will be present in the table. If specific metrics are given, only those rows/columns will be available in the table. |
|
excludedMetrics |
All |
no (default: none) |
Same arguments as for metrics, excluding “all”. |
Metrics that will be excluded from the table. Handy when a user wants to keep most of them. |
|
parameters |
Table of parameters (CA/NCA) |
no (default: all) |
One or more of parameters calculated in NCA or CA, including Cost if CA, or “all”. |
Parameters that will be included in the table. Used when table setting isn’t specified. |
|
excludedParameters |
Table of parameters (CA/NCA) |
no (default: none) |
Same arguments as for parameters, excluding “all”. |
Parameters that will be excluded from the table. Handy when a user wants to keep most of them. |
|
factors |
Anova table (BE) |
no (default: all) |
One or more of the headers of columns used in the BE linear model, including Residuals, or “all”. |
Factors included in the linear model. |
|
excludedFactors |
Anova table (BE) |
no (default: none) |
Same arguments as for factors, excluding “all”. |
Factors included in the linear model. |
|
ids |
Table of parameters (CA/NCA)
|
no (default: all) |
One or several of IDs present in the dataset, or “all”. |
IDs of subjects whose parameters should be shown in the table. The summary statistics will be calculated on all individuals, not just ones shown in the table. If not present, default is “all”. |
|
excludedIds |
Table of parameters (CA/NCA)
|
no (default: none) |
Same arguments as for ids, excluding “all”. |
IDs of subjects whose parameters should be excluded from the table. The summary statistics will be calculated on all individuals, not just ones shown in the table. |
|
covariates |
Table of parameters (CA/NCA) |
no (default: all) |
One or more of covariates present in the data set, or “all”. |
Which covariates to include in the table. |
|
covariatesAfterParameters |
Table of parameters (CA/NCA) |
no (default: true) |
true, false |
If covariates should be shown after parameters in the table. |
|
nbOccDisplayed |
Table of parameters (CA/NCA)
|
no (default: -1 meaning all) |
-1 or an integer |
-1 means all occasion levels are diplayed. 0 mean none of the occasion levels are diplayed. 1 means only the first occasion level is displayed, etc. |
Display
Display group of settings defines how the information in the tables will be displayed. Here is the list of all settings for the display group of settings:
|
Setting |
Table |
Required |
Possible values |
Description |
Example(s) |
|
units |
Table of parameters (CA/NCA)
|
no (default: true) |
true, false |
If true, units will be output next to parameters. |
units: true |
|
CDISCNames |
Table of parameters (CA/NCA)
|
no (default: false) |
true, false |
If true, CDISC names of parameters will be shown in the table. |
CDISCNames: true |
|
style |
All |
no (default: selected in Generate report pop-up) |
Name of table styles present in the template document. |
Microsoft Word document template style to apply to the table. This setting overrides the setting in the Generate report pop-up. |
style: “Medium Grid 1 – Accent 1” |
|
metricsDirection |
All |
no (default: vertical) |
vertical, horizontal |
Direction of metrics. |
metricsDirection: horizontal |
|
significantDigits |
All |
no (default: taken from Preferences) |
positive integers |
Number of significant digits values in the table will be rounded to. |
signifcantDigits: 3 |
|
trailingZeros |
All |
no (default: taken from Preferences) |
true, false |
If trailing zeros should be shown in the tables. |
trailingZeros: true |
|
inlineUnits |
Table of parameters (CA/NCA)
|
no (default: true) |
true, false |
If units should be inline with parameters. If false, there will be a new line between a parameter name and a unit. |
inlineUnits: false |
|
fitToContent |
All |
no (default: true) |
true, false |
If true, width of the table will be equal to the width of content, otherwise width of the table will be equal to the width of the page. |
fitToContent: false |
|
caption |
All |
no (default: no caption) |
a phrase inside quotation marks |
Caption that will appear next to the table. |
caption: “Individual NCA parameters” |
|
captionAbove |
All |
no (default: false) |
true, false |
If true, caption will be positioned above the table. If false, caption will be positioned below the table. |
captionAbove: true |
|
fontSize |
All |
no (default: 12) |
a number |
Font size of the table content (will not be applied to the caption). |
fontSize: 10 |
|
displayNaNs |
All |
no
|
true or false |
Display NCA parameters which could not be calculated as NaN instead of empty cell |
displayNaNs: true |
Stratification
Stratification group of settings defines how the table will be split. List of stratification settings:
|
Setting |
Table |
Required |
Possible values |
Description |
Example(s) |
|
state |
Table of parameters (CA/NCA) |
no |
Two possible subsettings:
|
Contains information of how to split the table. |
state: {split: [FORM]}
|
|
splitDirection |
Table of parameters (CA/NCA) |
no |
One or more of v, h |
In which direction the table should be split. Number of arguments corresponds to number of covariates by which the table was split. |
splitDirection: [v]
|
Let’s take a look at the demo project project_crossover_bioequivalence.pkx. It contains data from a 2×2 crossover bioequivalence study of two controlled release formulations of theophylline. We would like to generate a placeholder for the summary table of NCA parameters and split it across sequences and formulations. If we select that we only want to compute Cmax and AUClast, here is how a default placeholder looks like when we click on the placeholder button next to the NCA summary table and which table it produces:
<lixoftPLH>
data:
task: nca
metrics: [min, Q1, median, Q3, max, mean, SD, SE, CV, Ntot, Nobs, Nmiss, geoMean, geoSD, geoCV, harmMean]
parameters: [AUClast, Cmax]
display:
units: true
inlineUnits: true
metricsDirection: horizontal
significantDigits: 4
fitToContent: true
</lixoftPLH>

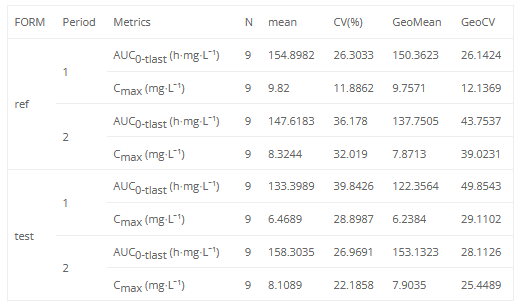
If we want to split the table by the period and the formulation, we can select the appropriate checkboxes on the right and the default placeholder will change automatically. However, doing this always splits the table vertically. We can also remove some of the statistics that we want to exclude from the table by modifying the metrics argument.
<lixoftPLH>
data:
task: nca
metrics: [min, median, max, mean, CV, Nobs, geoMean, geoCV]
parameters: [AUClast, Cmax]
display:
units: true
inlineUnits: true
metricsDirection: horizontal
significantDigits: 4
fitToContent: true
stratification:
state: {split: [FORM, Period]}
splitDirection: [v, v]
</lixoftPLH>
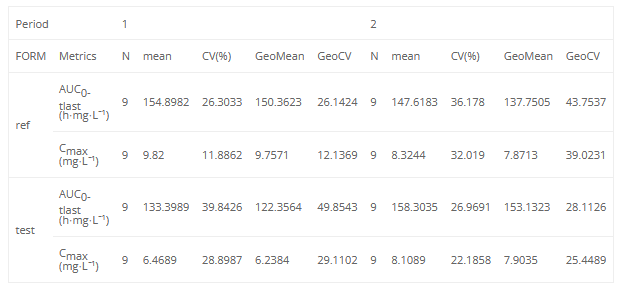
If we want to change the direction of splitting, for example, make a split by Period horizontal, instead of vertical, we can modify the splitDirection argument.
<lixoftPLH>
data:
task: nca
metrics: [Nobs, mean, CV, geoMean, geoCV]
parameters: [AUClast, Cmax]
display:
units: true
inlineUnits: true
metricsDirection: horizontal
significantDigits: 4
fitToContent: true
stratification:
state: {split: [FORM, Period]}
splitDirection: [v, h]
</lixoftPLH>
Renamings
Renamings setting can be provided to the placeholder to replace certain words or expressions that will appear in the table with a user-defined word or expression. We will explain the usage of renamings setting on a concrete example.
Let’s take a look at the demo project project_parallel_absBioavailability.pkx. The project contains data from 18 subjects, of which 9 received an IV formulation of a certain drug and other 9 received an oral formulation. Let’s say we want to use the Bioequivalence feature of PKanalix to calculate bioavailability of the oral formulation and generate a report. It would be suitable to put a bioequivalence confidence intervals table in the report, with certain renamings.
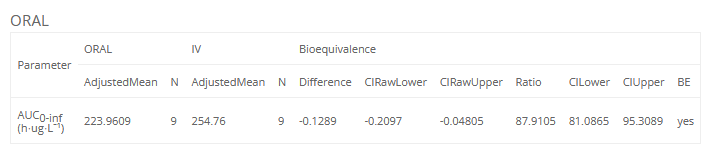
A generated placeholder for a BE confidence intervals table, with its default settings, is shown below, including the table it generates.
<lixoftPLH>
data:
task: be
table: confidenceIntervals
metrics: [AdjustedMean, N, Difference, CIRawLower, CIRawUpper, Ratio, CILower, CIUpper, BE]
parameters: [AUCINF_obs]
display:
units: true
inlineUnits: true
significantDigits: 4
fitToContent: true
</lixoftPLH>
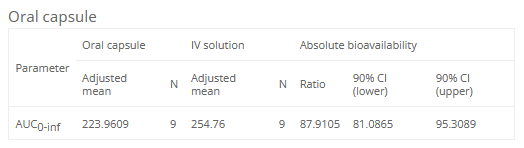
Let’s say we would like to hide some of the columns and rename some of the expressions in the table. For example, it would be convient to rename “Bioequivalence” to “Absolute bioavailability”, “IV” to “intravenous”, “ORAL” to “oral formulation”, and “CILower” to “90% CI (lower)”. We can then modify the placeholder to look like the one on the left and it will generate the table on the right.
<lixoftPLH>
data:
task: be
table: confidenceIntervals
metrics: [AdjustedMean, N, Ratio, CILower, CIUpper]
parameters: [AUCINF_obs]
renamings:
IV: "intravenous"
ORAL: "oral formulation"
Bioequivalence: "Absolute bioavailability"
CILower: "90% CI (lower)"
CIUpper: "90% CI (upper)"
AdjustedMean: "Adjusted mean"
</lixoftPLH>