
Cost function
The cost function that is minimized in the optimization performed during CA is described here. The cost is reported in the result tables after running CA, as individual cost in the table of individual parameters, and as total cost in a separate table, together with the likelihood and additional criteria.
Formulas for the cost function used in PKanalix are derived in the framework of generalized least squares described in the publication Banks, H. T., & Joyner, M. L. (2017). AIC under the framework of least squares estimation. Applied Mathematics Letters, 74, 33-45, with an additional scaling to put the same weight on different observation types.
The total cost function, shown in the cost table in the results, is a sum of individual costs per occasion (that is, summed over id-occ):
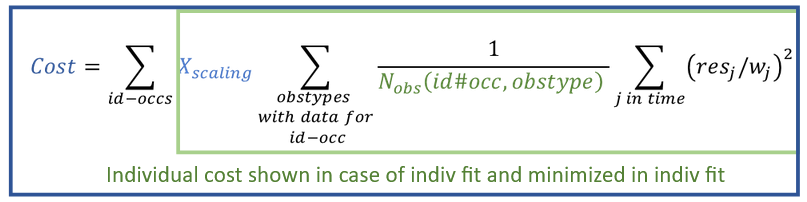
where in the above formula:
-
![]() denotes the number of observations for one individual, one occasion and one observation type (i.e., one model output mapped to data, such as parent and metabolite, or PK and PD, see here).
denotes the number of observations for one individual, one occasion and one observation type (i.e., one model output mapped to data, such as parent and metabolite, or PK and PD, see here). -
![]() are residuals at measurement times
are residuals at measurement times
![]() , where
, where
![]() are the predictions for each time point
are the predictions for each time point
![]() , and
, and
![]() are the observations from the dataset at that time.
are the observations from the dataset at that time. -
are weights, selected from the following:
![]() ,
,
![]() ,
,
![]() ,
,
,
,
depending on denominator of the selection in CA task > Settings > Calculations, as explained in this tutorial video.
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-25)'%3e%3cuse xlink:href='%23MJMATHI-4E' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(803%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6F' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-62' x='485' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-73' x='915' y='0'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-28' x='1882' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-69' x='2271' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-64' x='2617' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-23' x='3140' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6F' x='3974' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-63' x='4459' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-63' x='4893' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2C' x='5326' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6F' x='5772' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-62' x='6257' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-73' x='6687' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-74' x='7156' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-79' x='7518' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-70' x='8015' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-65' x='8519' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-29' x='8985' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-3)'%3e%3cuse xlink:href='%23MJMATHI-72' x='0' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-65' x='451' y='0'%3e%3c/use%3e%3cg transform='translate(918%2c0)'%3e%3cuse xlink:href='%23MJMATHI-73' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='663' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-3D' x='2056' y='0'%3e%3c/use%3e%3cg transform='translate(3113%2c0)'%3e%3cuse xlink:href='%23MJMATHI-59' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(581%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-70' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-72' x='503' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-65' x='955' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-64' x='1421' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-28' x='5170' y='0'%3e%3c/use%3e%3cg transform='translate(5559%2c0)'%3e%3cuse xlink:href='%23MJMATHI-74' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='511' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='6312' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2212' x='6924' y='0'%3e%3c/use%3e%3cg transform='translate(7925%2c0)'%3e%3cuse xlink:href='%23MJMATHI-59' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(581%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6F' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-62' x='485' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-73' x='915' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-28' x='9585' y='0'%3e%3c/use%3e%3cg transform='translate(9975%2c0)'%3e%3cuse xlink:href='%23MJMATHI-74' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='511' y='-213'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='10728' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-3)'%3e%3cuse xlink:href='%23MJMATHI-74' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='511' y='-213'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-7)'%3e%3cuse xlink:href='%23MJMATHI-59' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(581%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-70' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-72' x='503' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-65' x='955' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-64' x='1421' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-50)'%3e%3cuse xlink:href='%23MJMATHI-59' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(581%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6F' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-62' x='485' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-73' x='915' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
'%3e%3cuse xlink:href='%23MJMAIN-31' x='154' y='-50'%3e%3c/use%3e%3c/g%3e%3c/svg%3e)
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-3)'%3e%3cuse xlink:href='%23MJMATHI-58' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(828%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-73' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-63' x='469' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-61' x='903' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6C' x='1432' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='1730' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6E' x='2076' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-67' x='2677' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) is a scaling parameter given by:
is a scaling parameter given by:
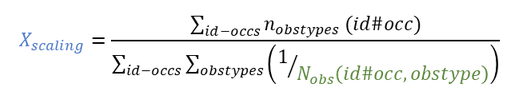
where
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-3)'%3e%3cuse xlink:href='%23MJMATHI-6E' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(600%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6F' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-62' x='485' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-73' x='915' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-74' x='1384' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-79' x='1746' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-70' x='2243' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-65' x='2747' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-73' x='3213' y='0'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-28' x='3304' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-69' x='3694' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-64' x='4039' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-23' x='4563' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6F' x='5396' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-63' x='5882' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-63' x='6315' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-29' x='6749' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) is the number of observation IDs mapped to a model output for one individual and one occasion. Note that if there is only one observation type (corresponding to one observation ID),
is the number of observation IDs mapped to a model output for one individual and one occasion. Note that if there is only one observation type (corresponding to one observation ID),
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-3)'%3e%3cuse xlink:href='%23MJMATHI-58' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(828%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-73' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-63' x='469' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-61' x='903' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6C' x='1432' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='1730' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6E' x='2076' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-67' x='2677' y='0'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-3D' x='3438' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-31' x='4495' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) and the cost function is a simple sum of squares over all observations, weighted by the weights
and the cost function is a simple sum of squares over all observations, weighted by the weights
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-3)'%3e%3cuse xlink:href='%23MJMATHI-77' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6A' x='1013' y='-213'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) .
.
Likelihood
The likelihood is not directly used in the optimization for CA, but it is possible to derive it based on the optimal cost obtained with the following formula (details in Banks et al.):
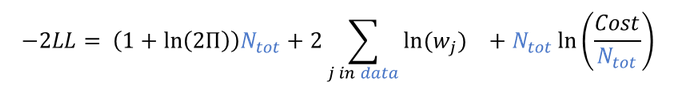
where
-
![]() stands for
stands for
![]() ,
, -
![]() is the total number of observations for all individuals, all occasions and all mapped model outputs,
is the total number of observations for all individuals, all occasions and all mapped model outputs, -
![]() are the weights as defined above.
are the weights as defined above.
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-50)'%3e%3cuse xlink:href='%23MJMAIN-2212' x='0' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-32' x='778' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-4C' x='1279' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-4C' x='1960' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-25)'%3e%3cuse xlink:href='%23MJMAIN-2212' x='0' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-32' x='778' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-D7' x='1501' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6C' x='2501' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6E' x='2800' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='3400' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-4C' x='3790' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-69' x='4471' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6B' x='4817' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-65' x='5338' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6C' x='5805' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-69' x='6103' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-68' x='6449' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6F' x='7025' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6F' x='7511' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-64' x='7996' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-29' x='8520' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-50)'%3e%3cuse xlink:href='%23MJMATHI-4E' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(803%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-74' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6F' x='361' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-74' x='847' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Additional Criteria
Additional information criteria are the Akaike Information Criteria (AIC) and the Bayesian Information Criteria (BIC). They can be used to compare models. They penalize -2LL by the number of parameters estimated, including the number of model parameters used for the optimization,
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-7)'%3e%3cuse xlink:href='%23MJMATHI-4E' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(803%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-70' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-61' x='503' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-72' x='1033' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-61' x='1484' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6D' x='2014' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) , the total number of observations,
, the total number of observations,
, and the number of observations for every subject-occasion,
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-25)'%3e%3cuse xlink:href='%23MJMATHI-4E' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(803%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6F' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-62' x='485' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-73' x='915' y='0'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-28' x='1882' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-69' x='2271' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-64' x='2617' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-23' x='3140' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6F' x='3974' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-63' x='4459' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-63' x='4893' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-29' x='5326' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) . This penalization enables comparing models with different levels of complexity. Indeed, with more parameters, a model can easily fit better (lower -2LL), but with too many parameters, a model loses predictive power and confidence in the parameter estimates. If not only the -2LL, but also the AIC and BIC criteria decrease after changing a model, it means that the increased likelihood is worth increasing the model complexity.
. This penalization enables comparing models with different levels of complexity. Indeed, with more parameters, a model can easily fit better (lower -2LL), but with too many parameters, a model loses predictive power and confidence in the parameter estimates. If not only the -2LL, but also the AIC and BIC criteria decrease after changing a model, it means that the increased likelihood is worth increasing the model complexity.

This formula simplifies if the “pooled fit” option is selected in the calculation settings of the CA task:

AIC derivation in the case of individual fits
The total AIC for all individuals penalizes -2LL with 2 x the number of parameters used in the optimization. For the structural model, we estimate
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-7)'%3e%3cuse xlink:href='%23MJMATHI-4E' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(803%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-70' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-61' x='503' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-72' x='1033' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-61' x='1484' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6D' x='2014' y='0'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-22C5' x='3171' y='0'%3e%3c/use%3e%3cg transform='translate(3671%2c0)'%3e%3cuse xlink:href='%23MJMATHI-4E' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(803%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-64' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-23' x='869' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6F' x='1702' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-63' x='2188' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-63' x='2621' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) parameters, where
is the number of parameters in the structural model and
parameters, where
is the number of parameters in the structural model and
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-7)'%3e%3cuse xlink:href='%23MJMATHI-4E' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(803%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-64' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-23' x='869' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6F' x='1702' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-63' x='2188' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-63' x='2621' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) is the number of subject-occasions (since there is a set of parameters estimated for each id#occ). For the statistical model, we also implicitly estimate a parameter
is the number of subject-occasions (since there is a set of parameters estimated for each id#occ). For the statistical model, we also implicitly estimate a parameter
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-68)'%3e%3cuse xlink:href='%23MJMATHI-3C3' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-32' x='810' y='513'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) , which is the variance of the residual error model shared by all individuals (it is derived using the sum of squares of residuals as described in Banks et al.). Therefore, AIC penalizes -2LL by
, which is the variance of the residual error model shared by all individuals (it is derived using the sum of squares of residuals as described in Banks et al.). Therefore, AIC penalizes -2LL by
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-7)'%3e%3cuse xlink:href='%23MJMAIN-32' x='0' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='500' y='0'%3e%3c/use%3e%3cg transform='translate(890%2c0)'%3e%3cuse xlink:href='%23MJMATHI-4E' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(803%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-70' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-61' x='503' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-72' x='1033' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-61' x='1484' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6D' x='2014' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-22C5' x='4061' y='0'%3e%3c/use%3e%3cg transform='translate(4561%2c0)'%3e%3cuse xlink:href='%23MJMATHI-4E' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(803%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-69' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-64' x='345' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-23' x='869' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6F' x='1702' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-63' x='2188' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-63' x='2621' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='7847' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-31' x='8848' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-29' x='9348' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) .
.
BIC derivation in the case of individual fits
The total BIC penalizes -2LL by (number of parameters) x ln(number of data points). In this case, we should distinguish between the data for each id#occ, which is used to estimate
parameters, and the data for all individuals, which is used together to estimate the residual variance
. To penalize each individual’s data in the estimation of
, we add the term
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-7)'%3e%3cuse xlink:href='%23MJMATHI-4E' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(803%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-70' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-61' x='503' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-72' x='1033' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-61' x='1484' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6D' x='2014' y='0'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-D7' x='3171' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6C' x='4171' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6E' x='4470' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='5070' y='0'%3e%3c/use%3e%3cg transform='translate(5460%2c0)'%3e%3cuse xlink:href='%23MJMATHI-4E' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(803%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6F' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-62' x='485' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-73' x='915' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-28' x='7342' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-69' x='7732' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-64' x='8077' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-23' x='8601' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6F' x='9434' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-63' x='9920' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-63' x='10353' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-29' x='10787' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-29' x='11176' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) for each id#occ. To penalize the estimation of the error model parameter with all the observations (substitution of
for each id#occ. To penalize the estimation of the error model parameter with all the observations (substitution of
'%3e%3cuse xlink:href='%23MJMATHI-3C3' x='154' y='-50'%3e%3c/use%3e%3c/g%3e%3c/svg%3e) as described in Banks et al.), we add the term
as described in Banks et al.), we add the term
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-25)'%3e%3cuse xlink:href='%23MJMAIN-31' x='0' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-D7' x='722' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6C' x='1723' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-6E' x='2021' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='2622' y='0'%3e%3c/use%3e%3cg transform='translate(3011%2c0)'%3e%3cuse xlink:href='%23MJMATHI-4E' x='0' y='0'%3e%3c/use%3e%3cg transform='translate(803%2c-150)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-74' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-6F' x='361' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-74' x='847' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='4769' y='0'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) .
.