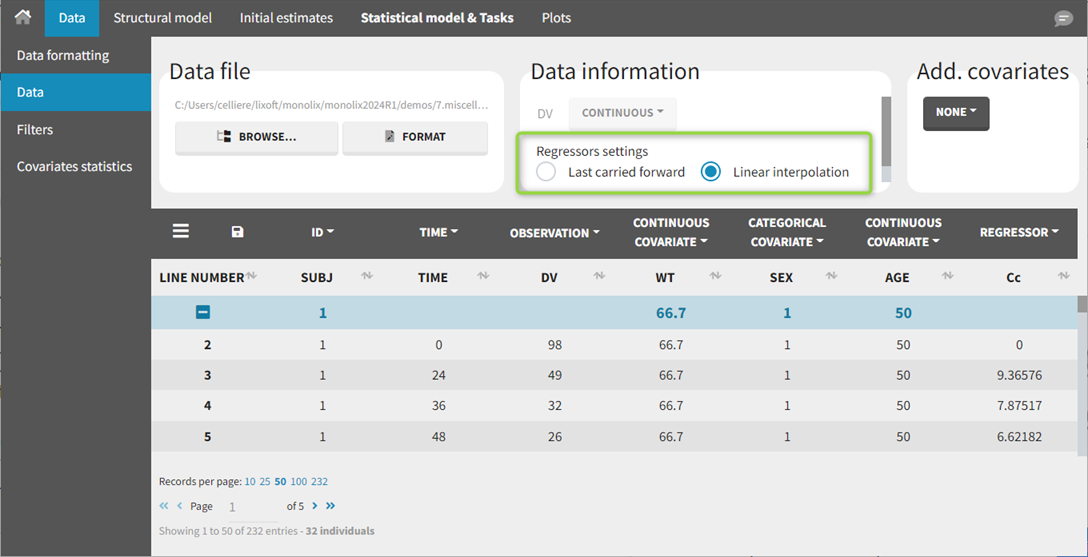
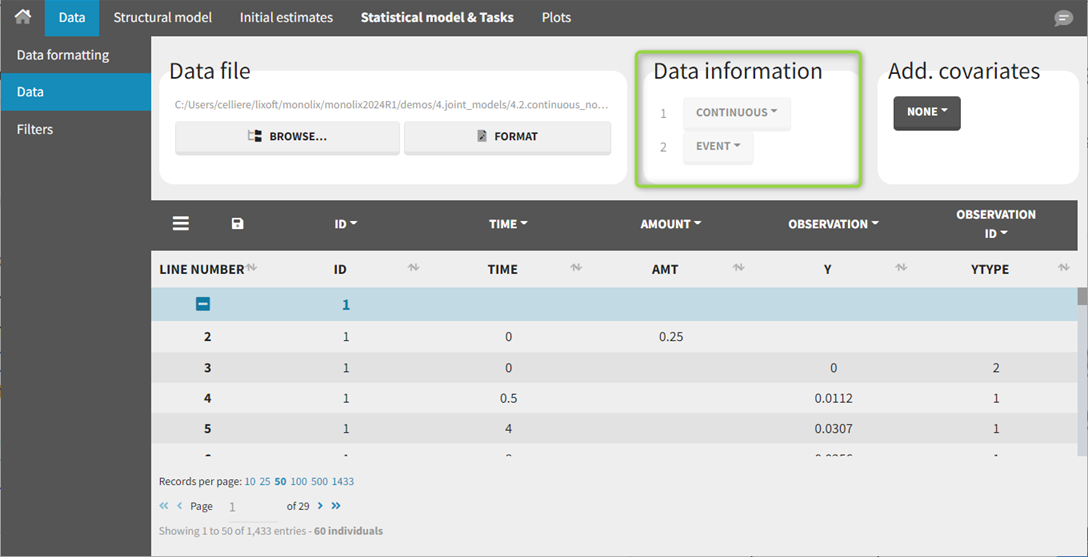
During and after the data tagging procedure, the Data information section is available in the Data tab.
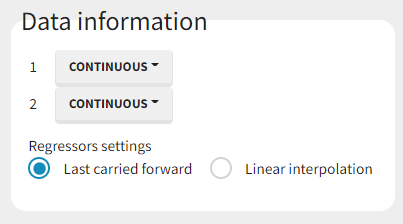
The Data information section contains:
-
dropdown(s) for definition of observation types,
-
regressor settings (if at least one of the columns was tagged as a regressor column).
Observation types
There are three possible types of observations in Monolix:
-
continuous: The observation is continuous and can take any value within a range. For example, a concentration is a continuous observation.
-
count/categorical: The observation values can take values only in a finite categorical space. For example, the observation can be a categorical observation (an effect can be observed as “low”, “medium”, or “high”) or a count observation over a defined time (the number of epileptic crisis in a week).
-
event: The observation is an event, for example the time of death.
For each OBSERVATION ID, the type of observations must be specified by the user in the interface. Depending on the choice, the data will be displayed in the Observed Data plot in different ways (e.g spaghetti plot for continuous data and Kaplan-Meier plot for event data). The mapping of model outputs and observations from the dataset will also take into account the data type (e.g a model outptu of type “event” can only be mapped to an observation that is also an “event”). Once a model has been selected, the choice of the data types are locked (because they are enforced by the model output type).
Regressor settings
If columns have been tagged as REGRESSORS, the interpolation method for the regressors can be chosen.
Regressors are defined over time for a finite number of time points. In between those time points, the regressor value can be interpolated in two different ways:
-
last value carried forward: if we have defined
at time
and
at time
-
for
,
[first defined value is used]
-
for
,
[previous value is used]
-
for
,
[previous value is used]
-
-
linear interpolation:
-
for
,
[first defined value is used]
-
for
,
![]() [linear interpolation is used]
[linear interpolation is used] -
for
,
[previous value is used]
-
'%3e%3cg transform='translate(167%2c0)'%3e%3cg transform='translate(-13%2c0)'%3e%3cg transform='translate(0%2c-13)'%3e%3cuse xlink:href='%23MJMATHI-72' x='0' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-65' x='451' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-67' x='918' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='1398' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-74' x='1788' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-29' x='2149' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-3D' x='2816' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-72' x='3873' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-65' x='4324' y='0'%3e%3c/use%3e%3cg transform='translate(4791%2c0)'%3e%3cuse xlink:href='%23MJMATHI-67' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-41' x='675' y='-230'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-2B' x='6121' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-28' x='7122' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMATHI-74' x='7511' y='0'%3e%3c/use%3e%3cuse xlink:href='%23MJMAIN-2212' x='8095' y='0'%3e%3c/use%3e%3cg transform='translate(9096%2c0)'%3e%3cuse xlink:href='%23MJMATHI-74' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-41' x='511' y='-230'%3e%3c/use%3e%3c/g%3e%3cuse xlink:href='%23MJMAIN-29' x='10088' y='0'%3e%3c/use%3e%3cg transform='translate(10477%2c0)'%3e%3cg transform='translate(120%2c0)'%3e%3crect stroke='none' width='3540' height='60' x='0' y='220'%3e%3c/rect%3e%3cg transform='translate(60%2c596)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-72' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-65' x='451' y='0'%3e%3c/use%3e%3cg transform='translate(649%2c0)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-67' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.5)' xlink:href='%23MJMATHI-42' x='675' y='-342'%3e%3c/use%3e%3c/g%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2212' x='2032' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-72' x='2811' y='0'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-65' x='3262' y='0'%3e%3c/use%3e%3cg transform='translate(2636%2c0)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-67' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.5)' xlink:href='%23MJMATHI-41' x='675' y='-342'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3cg transform='translate(791%2c-369)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-74' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.5)' xlink:href='%23MJMATHI-42' x='511' y='-213'%3e%3c/use%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMAIN-2212' x='998' y='0'%3e%3c/use%3e%3cg transform='translate(1256%2c0)'%3e%3cuse transform='scale(0.707)' xlink:href='%23MJMATHI-74' x='0' y='0'%3e%3c/use%3e%3cuse transform='scale(0.5)' xlink:href='%23MJMATHI-41' x='511' y='-230'%3e%3c/use%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
The interpolation is used to obtain the regressor value at times not defined in the dataset. This is necessary to integrate ODE-based models (which are using an internal adaptative time step), or obtain prediction on a fine grid for the plots (e.g in the Individuals fits) for instance.
When some dataset lines have a missing regressor value (dot “.”), the same interpolation method is used.